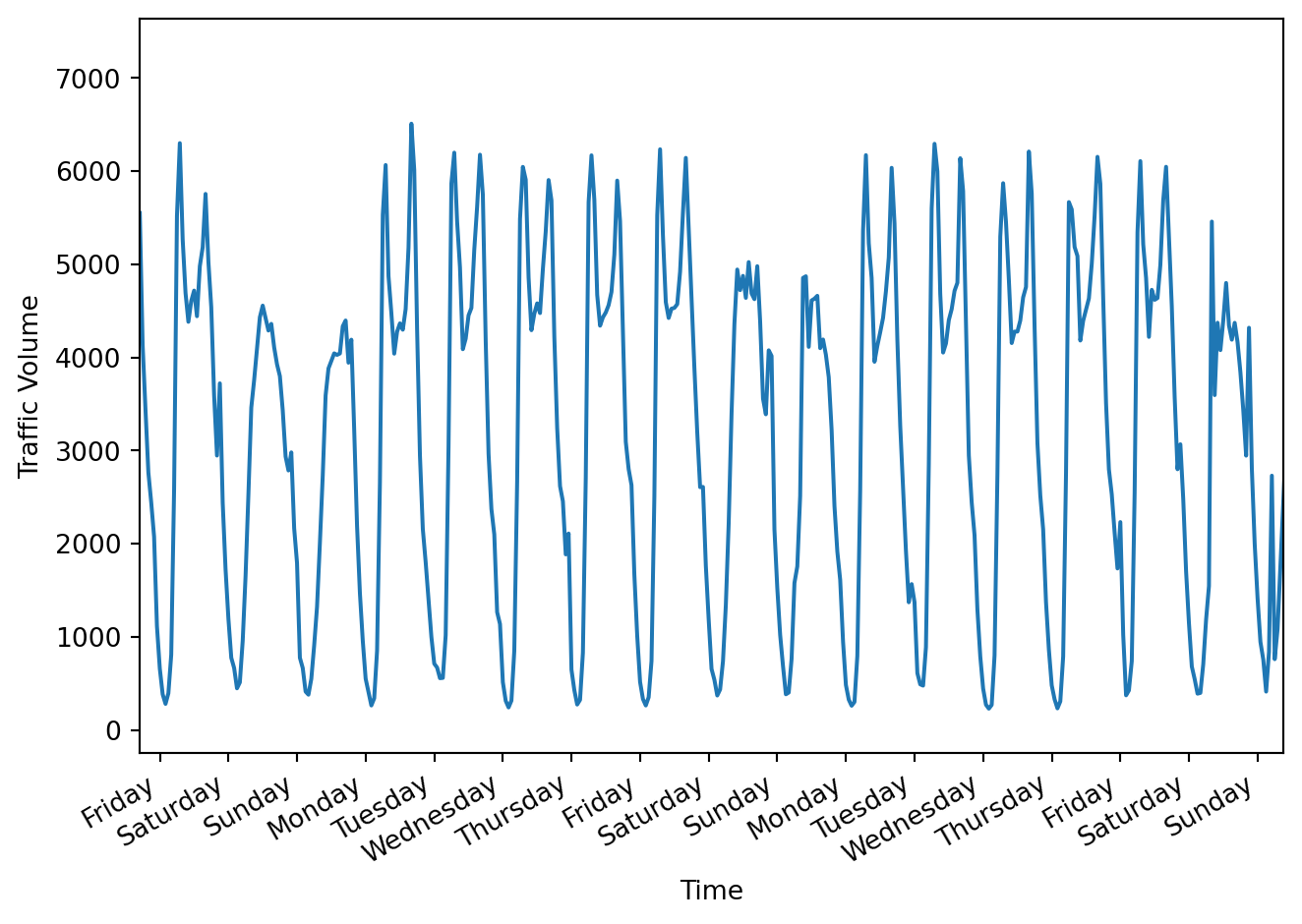
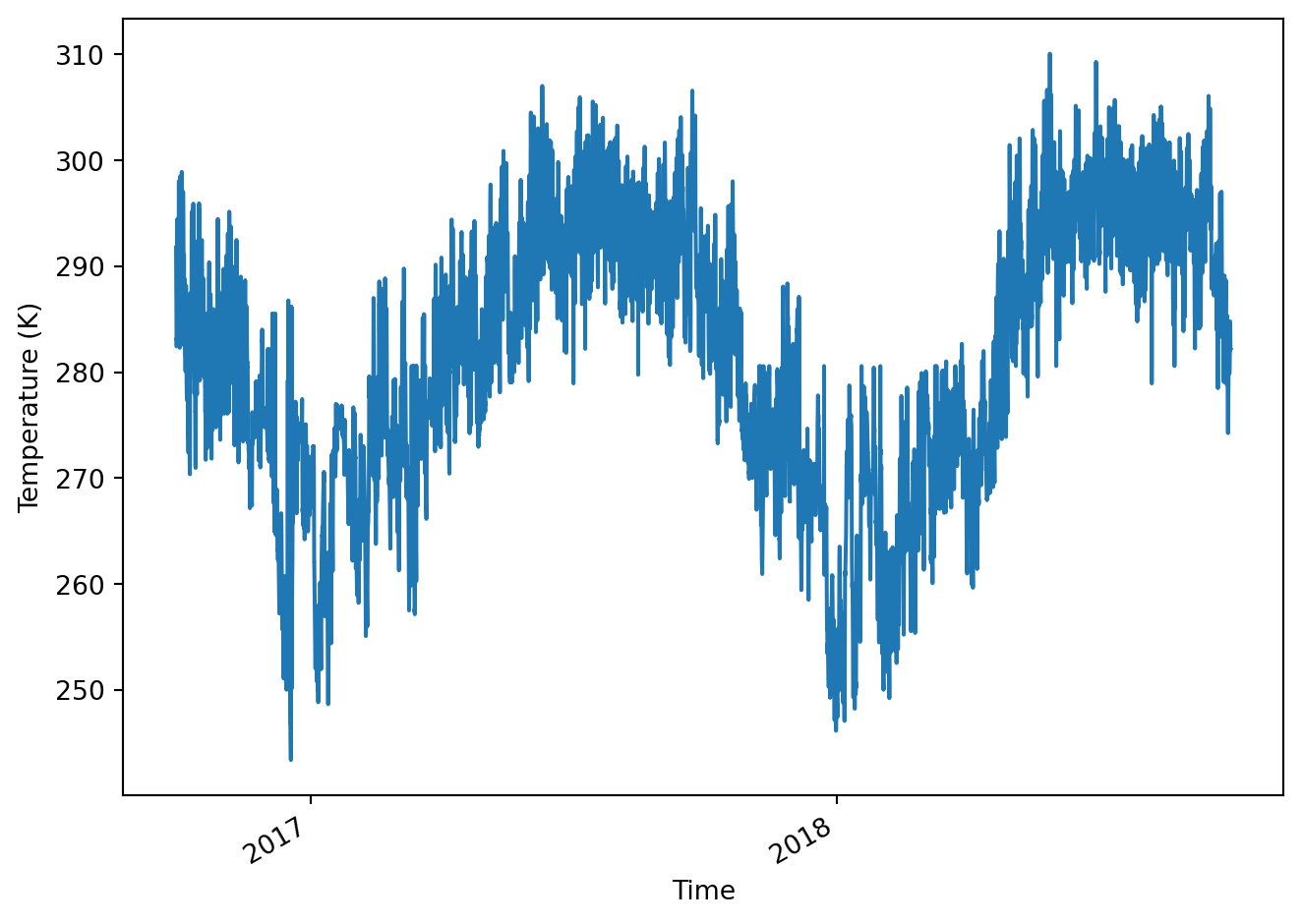
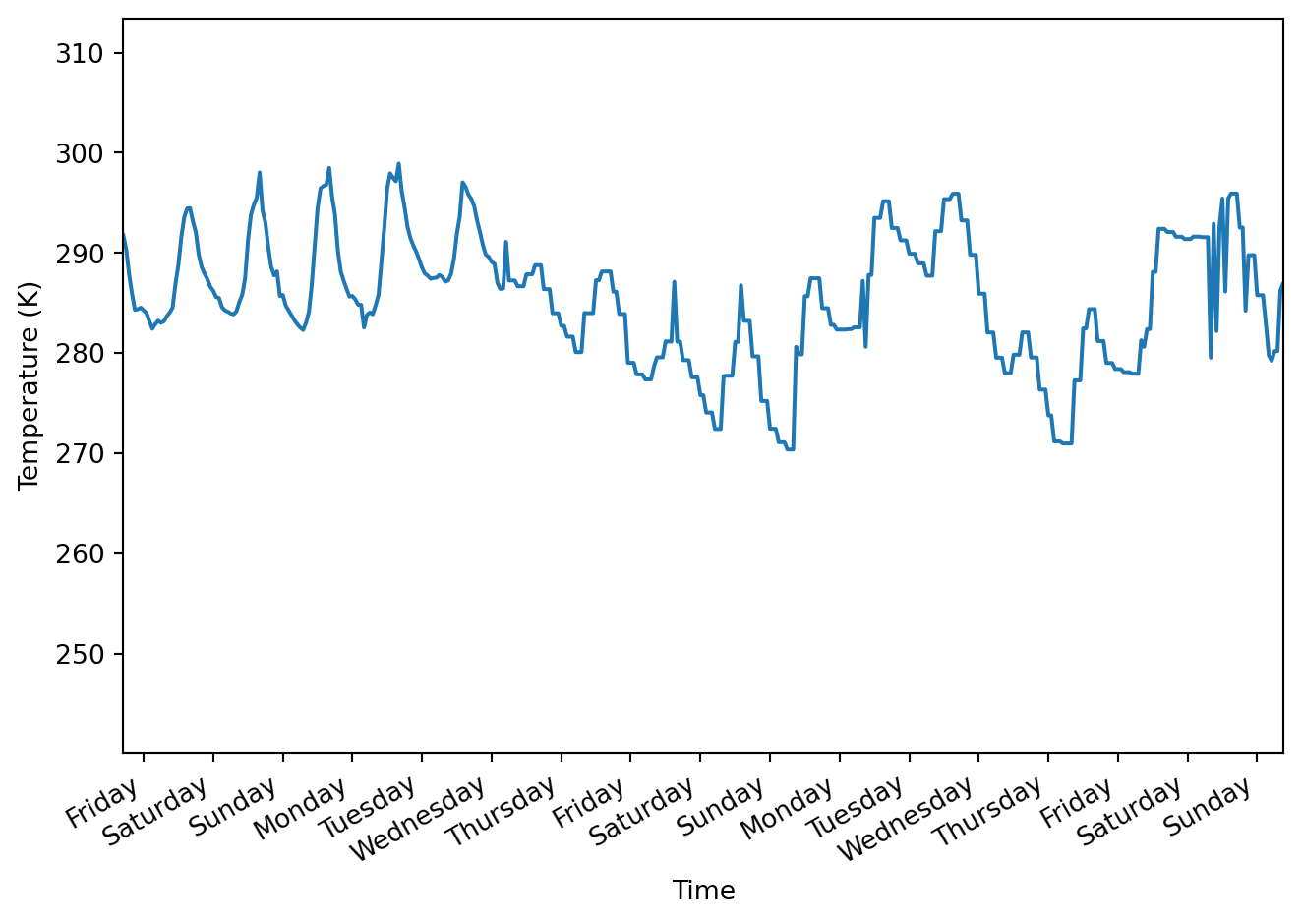
import pandas as pd
df = pd.read_csv("data/traffic.csv")
df.head()| date_time | temp | rain_1h | snow_1h | clouds_all | traffic_volume | |
|---|---|---|---|---|---|---|
| 0 | 2016-09-29 17:00:00 | 291.75 | 0.0 | 0 | 0 | 5551.0 |
| 1 | 2016-09-29 18:00:00 | 290.36 | 0.0 | 0 | 0 | 4132.0 |
| 2 | 2016-09-29 19:00:00 | 287.86 | 0.0 | 0 | 0 | 3435.0 |
| 3 | 2016-09-29 20:00:00 | 285.91 | 0.0 | 0 | 0 | 2765.0 |
| 4 | 2016-09-29 21:00:00 | 284.31 | 0.0 | 0 | 0 | 2443.0 |