EDA(Exploratory Data Analysis)
: 데이터의 특징과 데이터에 내재된 관계를 알아내기 위해 그래프와 통계적 분석 방법을 활용하여 탐구하는 것
주제
저항성 강조: 부분적 변동(이상치 등)에 대한 민감성 확인
잔차 계산
자료변수의 재표현: 변수를 적당한 척도로 바꾸는 것
그래프를 통한 현시성
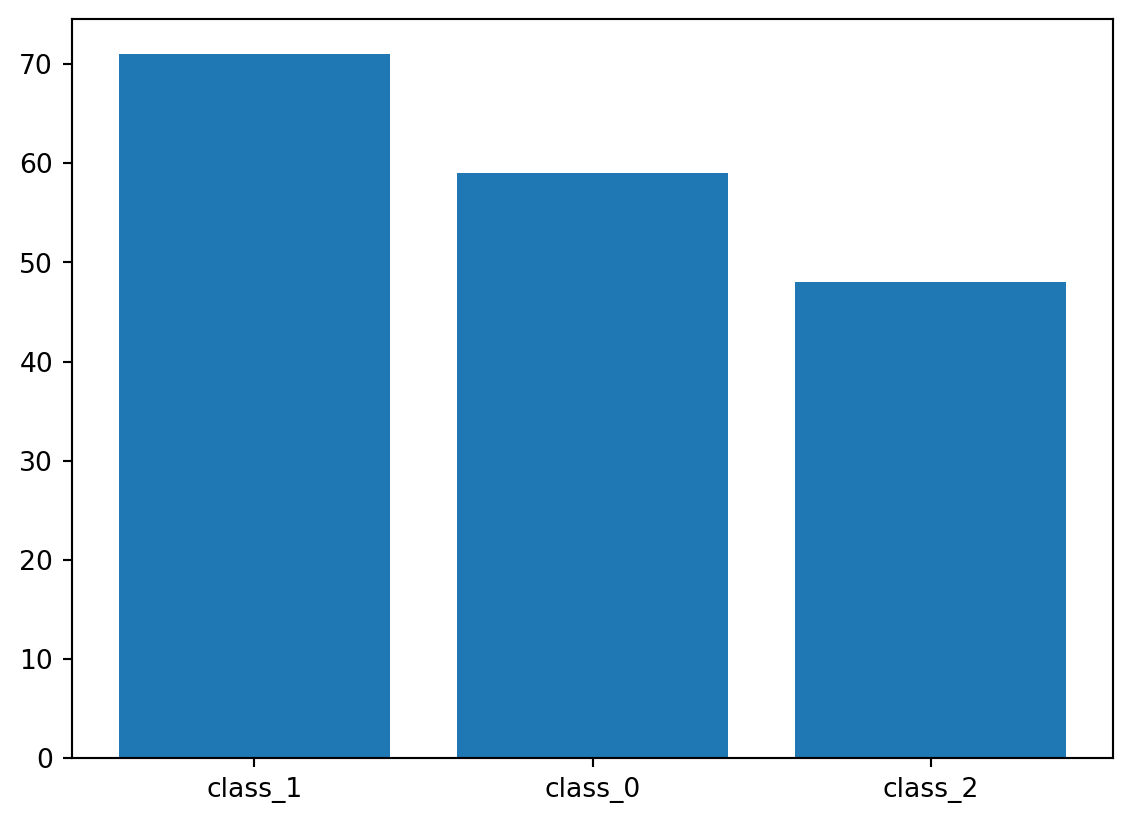
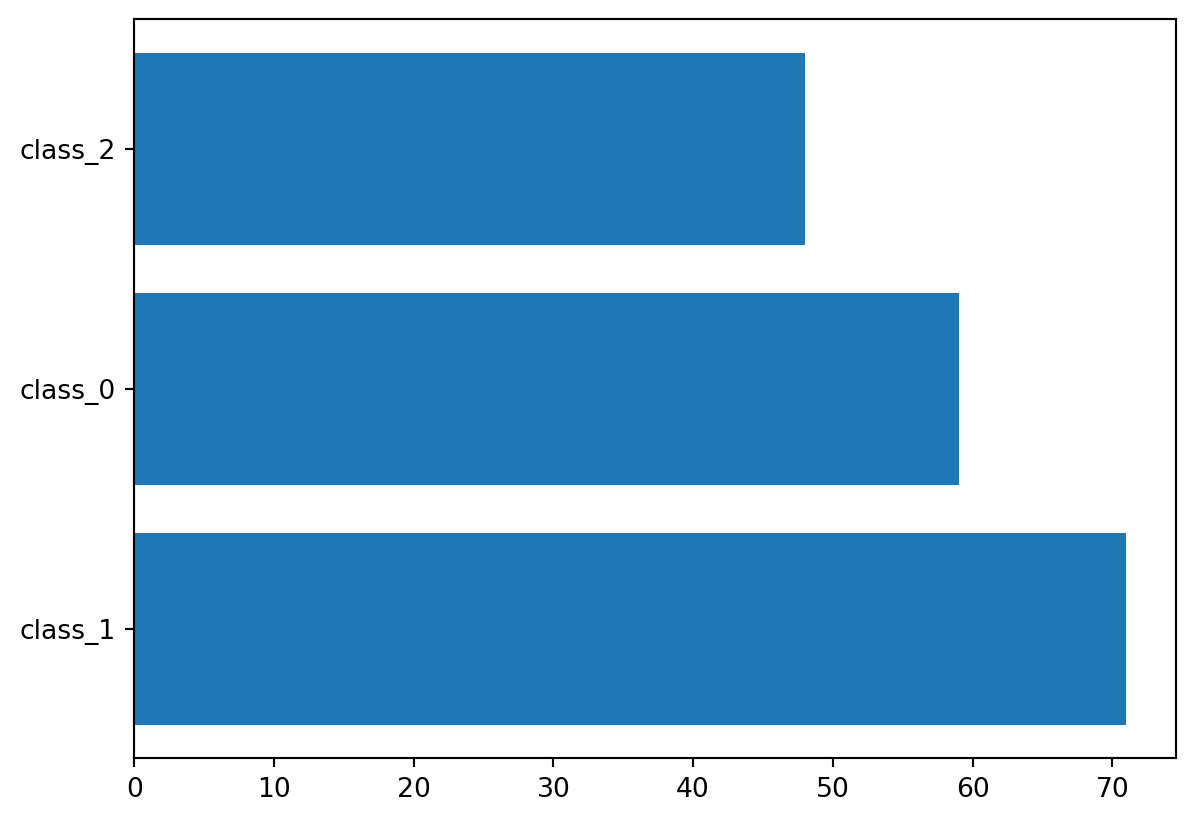
막대 그래프
범주형 데이터를 요약하고 시각적으로 비교하는 데 활용
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_wine= load_wine()= pd.DataFrame(wine_load.data, columns= wine_load.feature_names)'Class' ] = wine_load.target'Class' ] = wine['Class' ].map ({0 : 'class_0' , 1 : 'class_1' , 2 : 'class_2' })= wine['Class' ].value_counts()
Class
class_1 71
class_0 59
class_2 48
Name: count, dtype: int64
# 수직 막대 = 0.8 , bottom= None , align = 'center' )
# 수평 막대 = 0.8 , left= None , align = 'center' )
각 범주의 값의 갯수 차이가 극단적인지 확인한다. 극단적일 경우, 전처리 과정에서 업/다운 샘플링 등을 통해 갯수가 유사해지도록 조정해야한다.
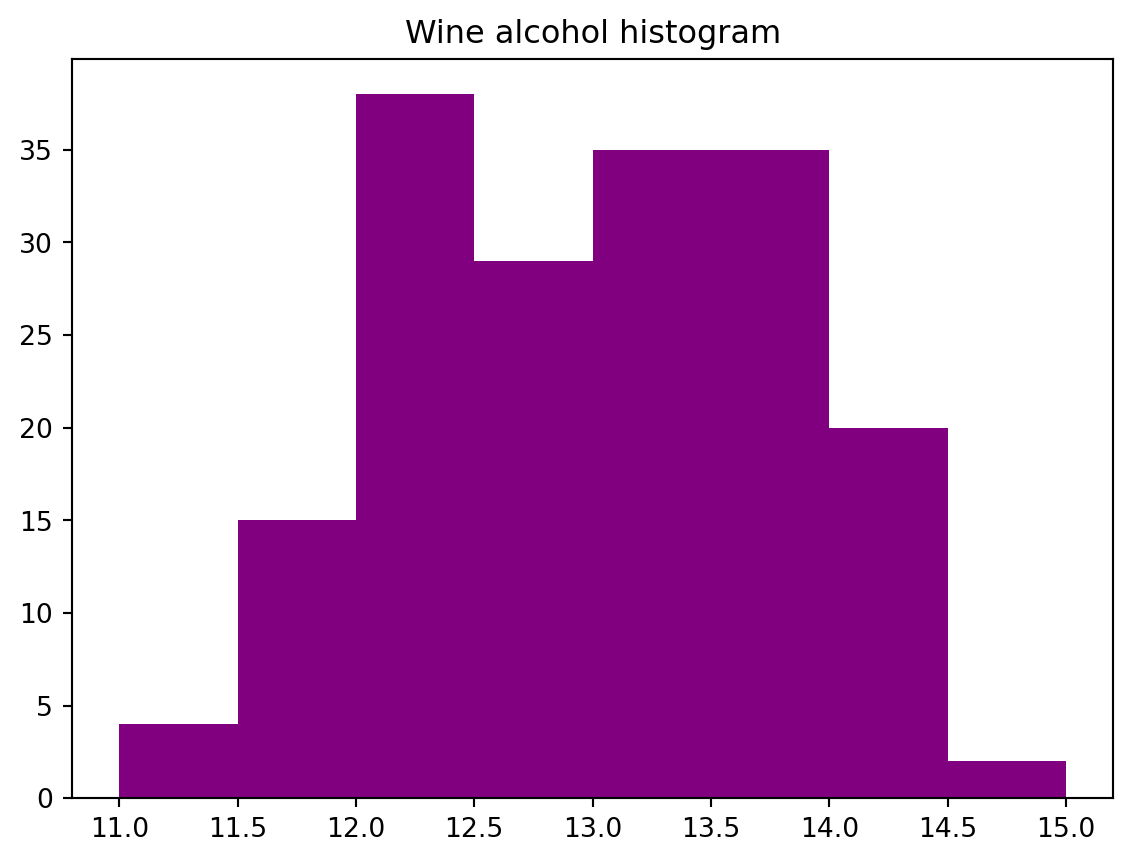
히스토그램
연속형 데이터의 분포를 확인하는 데 활용
'Wine alcohol histogram' )'alcohol' , bins= 8 , range = (11 , 15 ), color= 'purple' , data= wine)
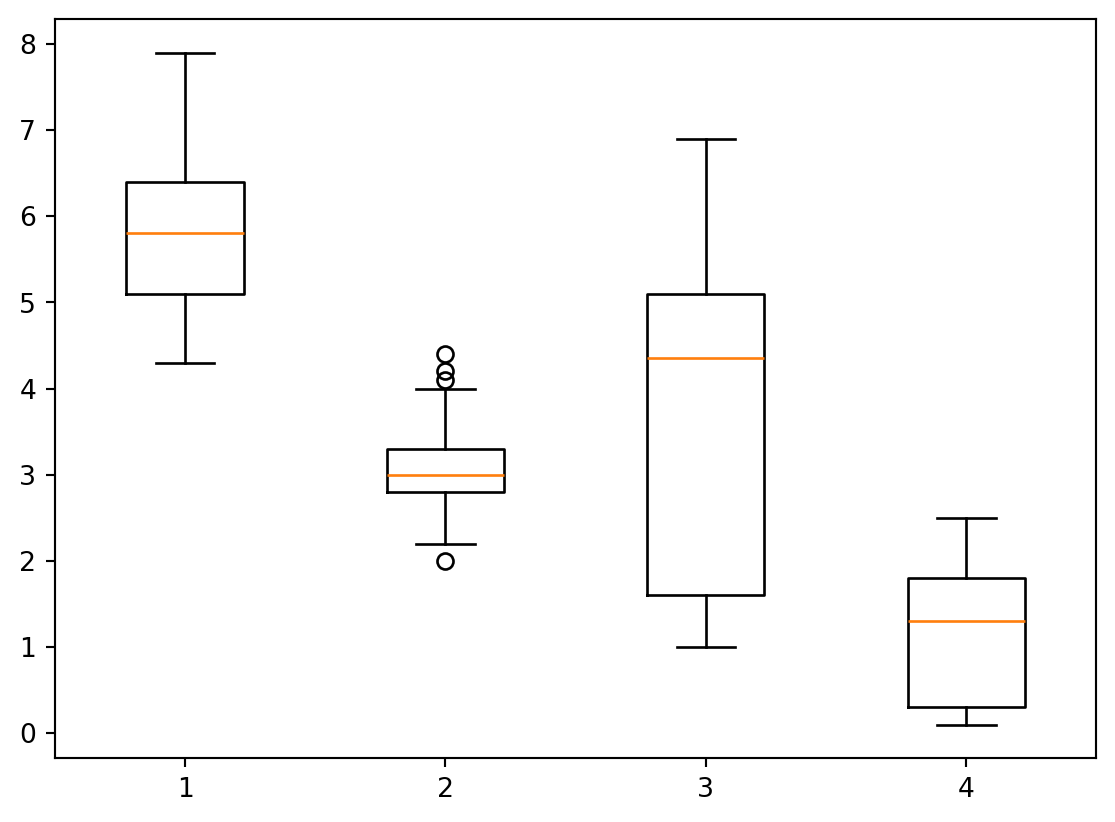
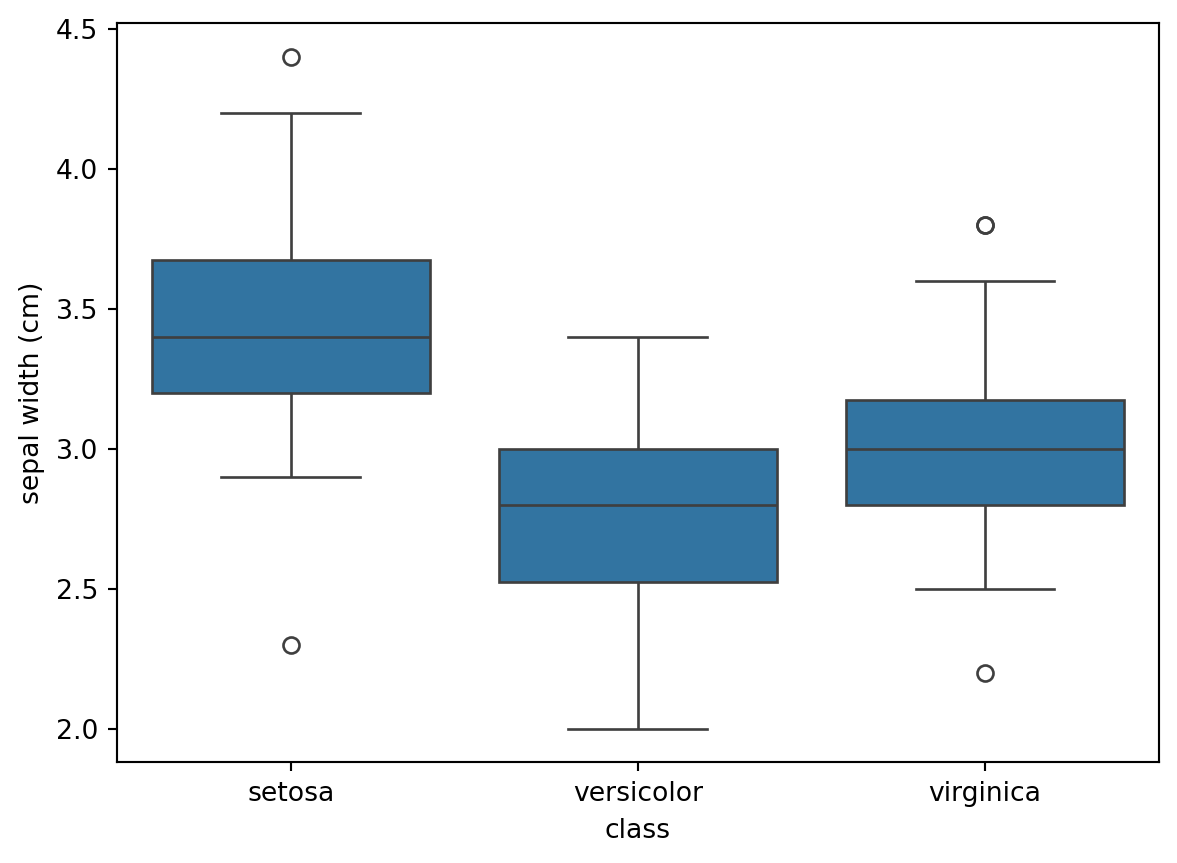
box plot
수치형 변수의 분포를 확인하는 그래프
from sklearn.datasets import load_iris= load_iris()= pd.DataFrame(iris_load.data, columns= iris_load.feature_names)'class' ] = iris_load.target'class' ] = iris['class' ].map ({0 : 'setosa' , 1 : 'versicolor' , 2 : 'virginica' })= 'class' ))
import seaborn as sns= "class" , y= "sepal width (cm)" , data= iris)
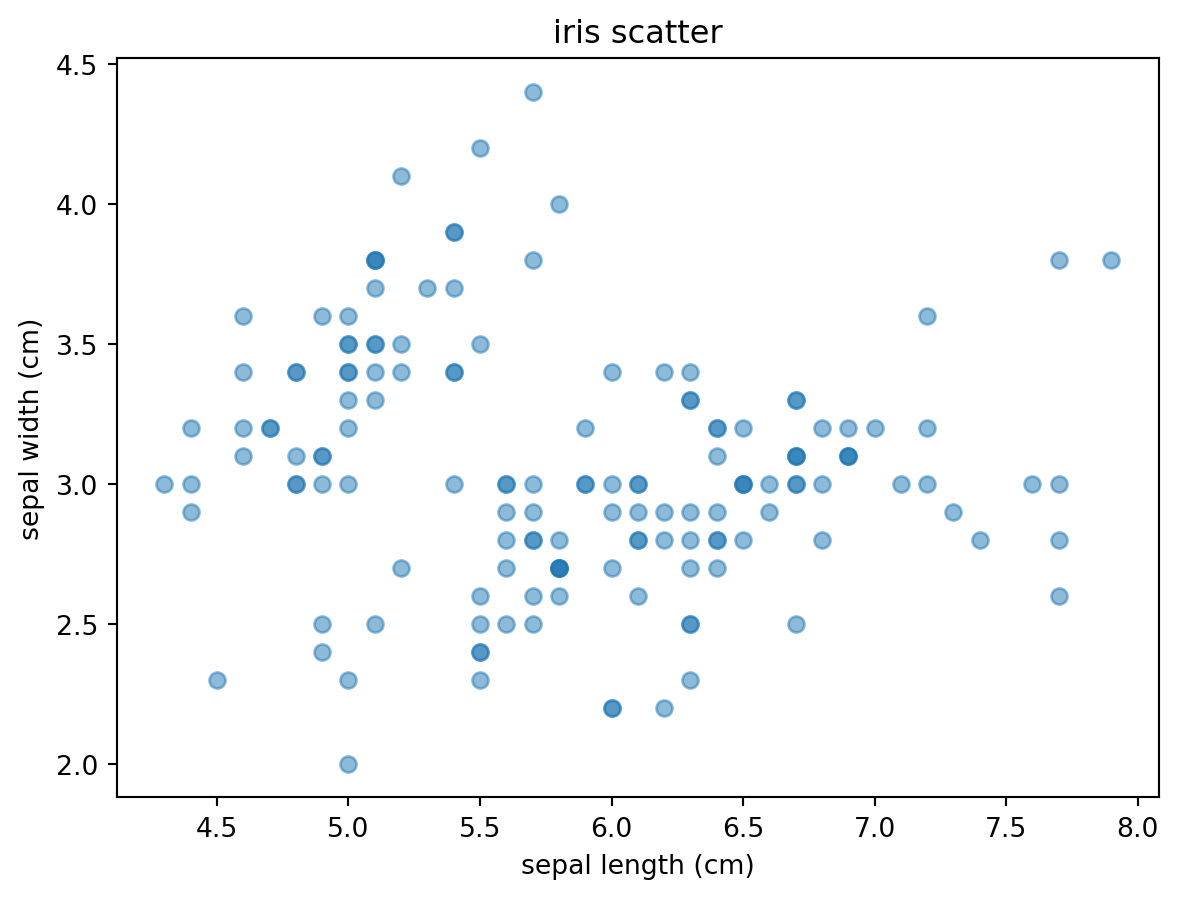
산점도
두 개의 수치형 변수의 분포와 관계를 확인하는 그래프
'iris scatter' )'sepal length (cm)' )'sepal width (cm)' )'sepal length (cm)' , 'sepal width (cm)' , data= iris, alpha= 0.5 )
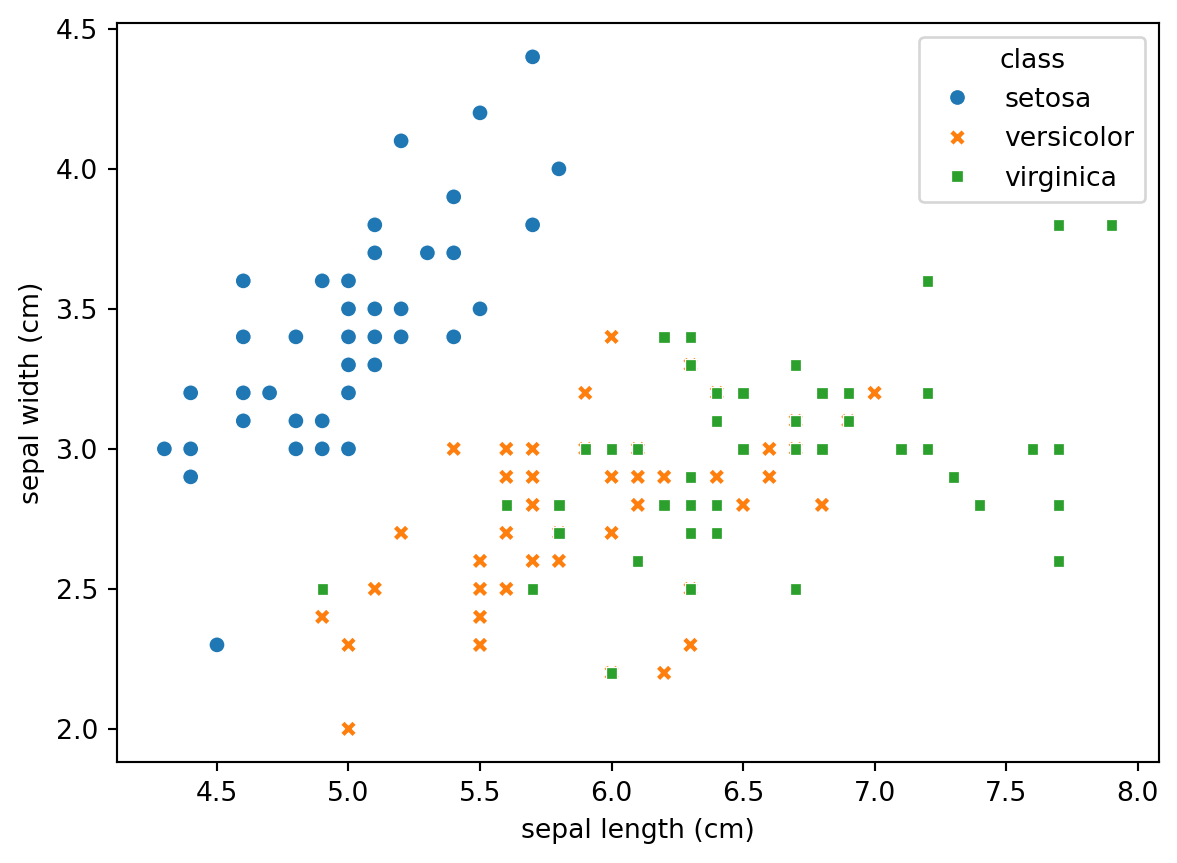
= 'sepal length (cm)' , y= 'sepal width (cm)' , hue= 'class' , data= iris, style= 'class' )
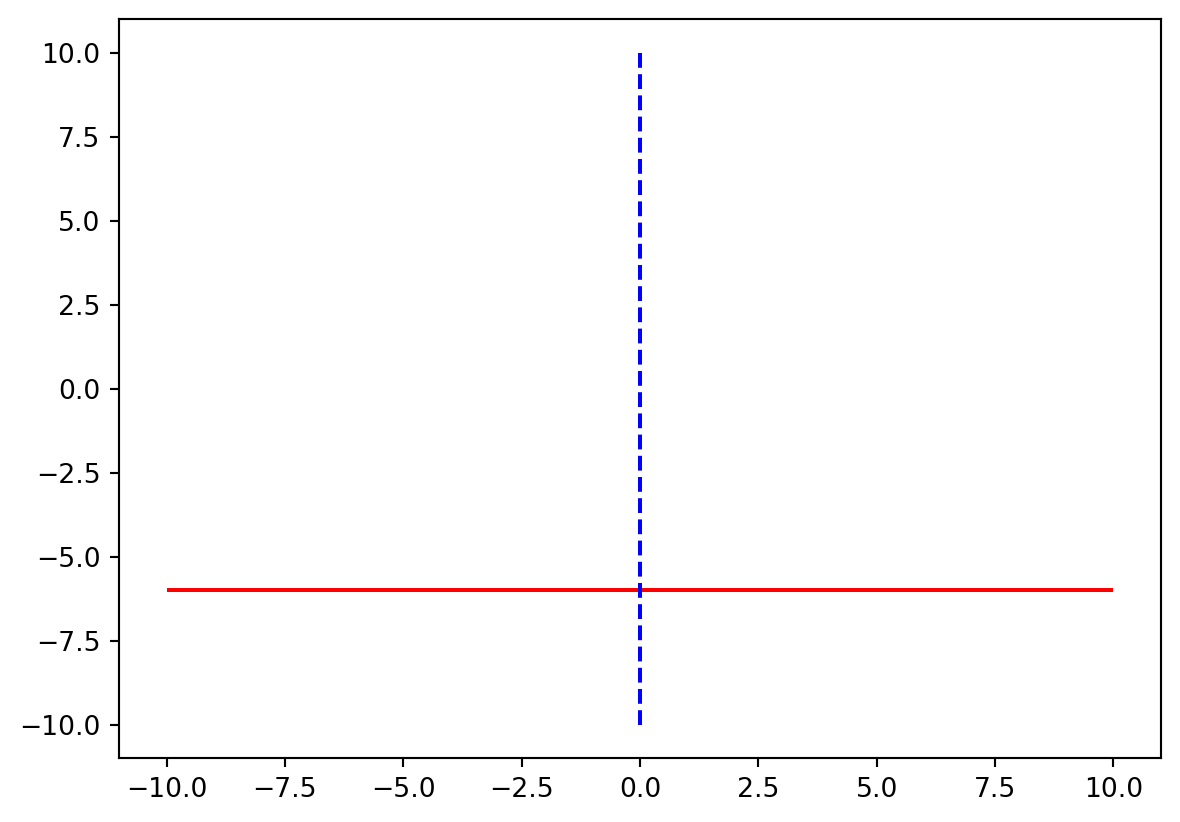
선그래프
수평 / 수직 선
=- 6 , xmin=- 10 , xmax= 10 , colors= 'red' , linestyles= 'solid' )= 0 , ymin=- 10 , ymax= 10 , colors= 'blue' , linestyles= 'dashed' )
함수식
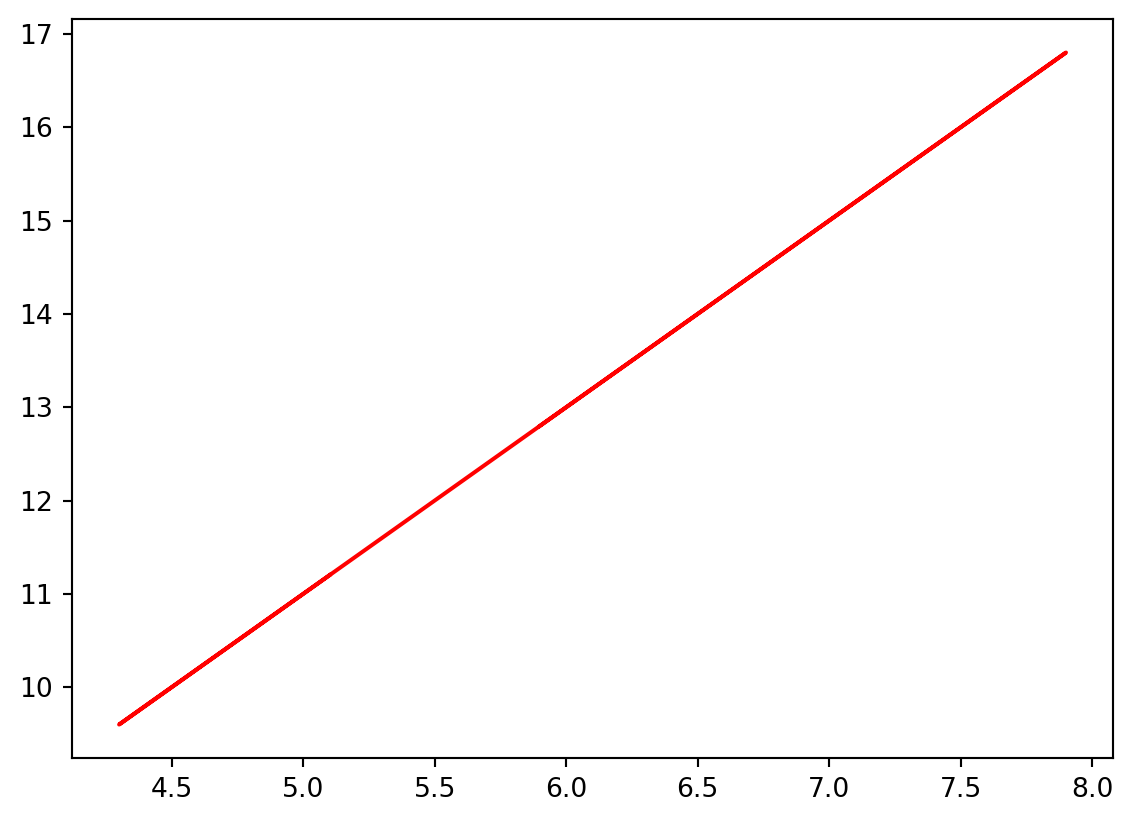
def linear_func(x):return 2 * x + 1 = iris['sepal length (cm)' ]= 'red' )
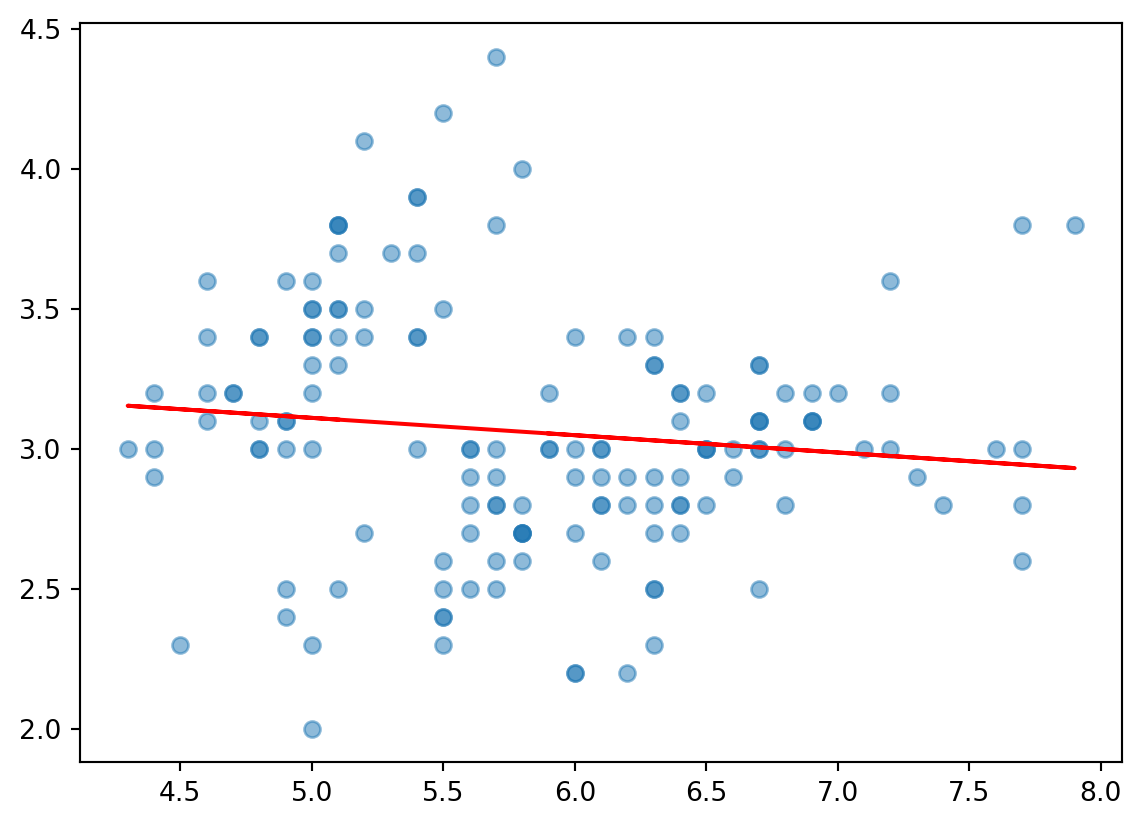
회귀선
import numpy as np= iris['sepal length (cm)' ], iris['sepal width (cm)' ]= 0.5 )= np.polyfit(X, Y, 1 )* X + b, c= 'red' )
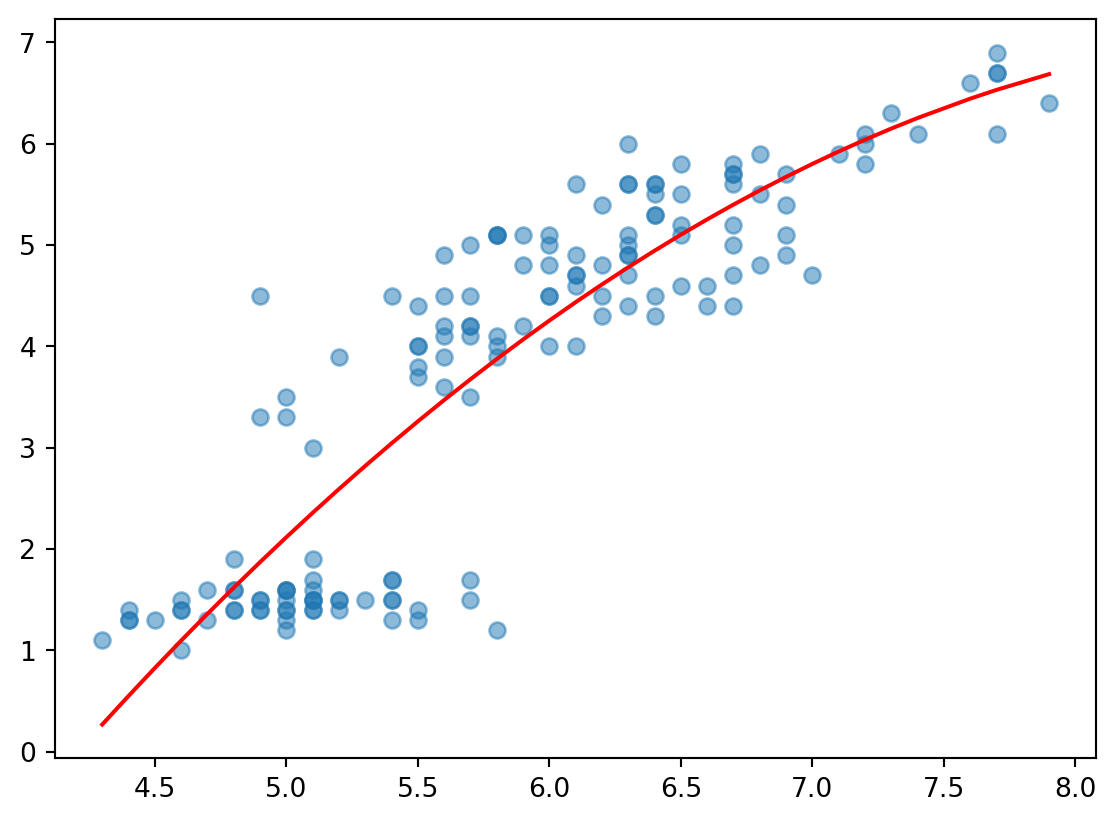
2차 이상의 그래프는 X값에 대하여 정렬해야 한다.
= iris.sort_values(by= 'sepal length (cm)' )= iris2['sepal length (cm)' ], iris2['petal length (cm)' ]= np.polyfit(X, Y, 2 )= 0.5 )+ b1* X + b2* X** 2 , color= 'red' )
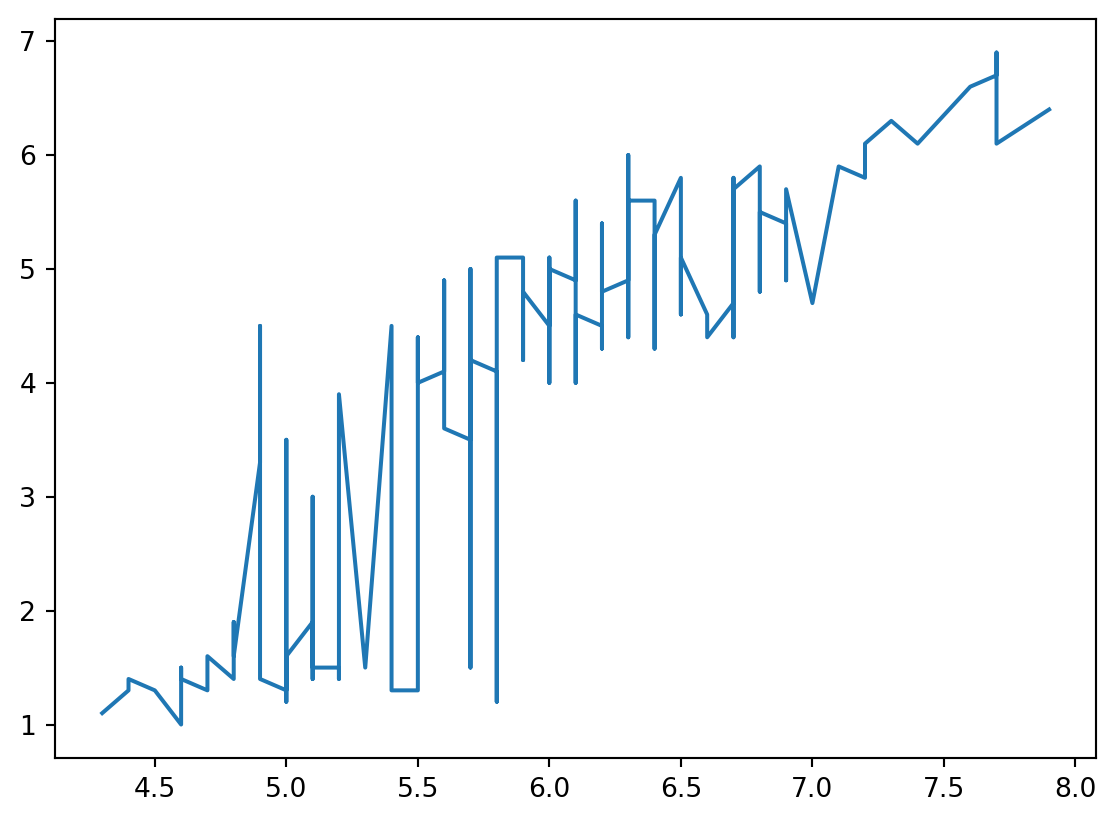
꺾은선
'sepal length (cm)' , 'petal length (cm)' , data= iris2)
상관관계 시각화
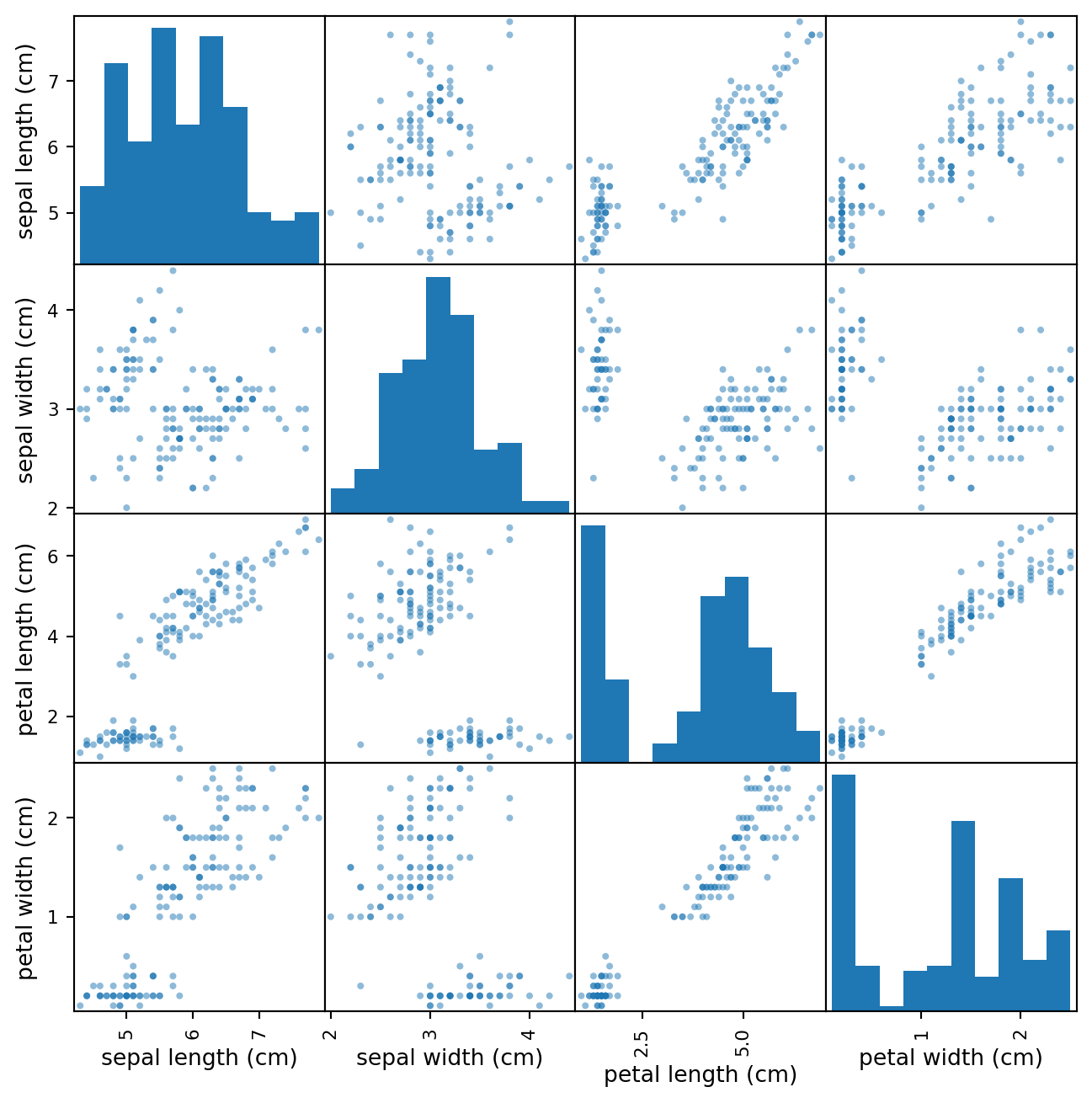
산점도 행렬
from pandas.plotting import scatter_matrix= 0.5 , figsize= (8 , 8 ), diagonal= 'hist' )
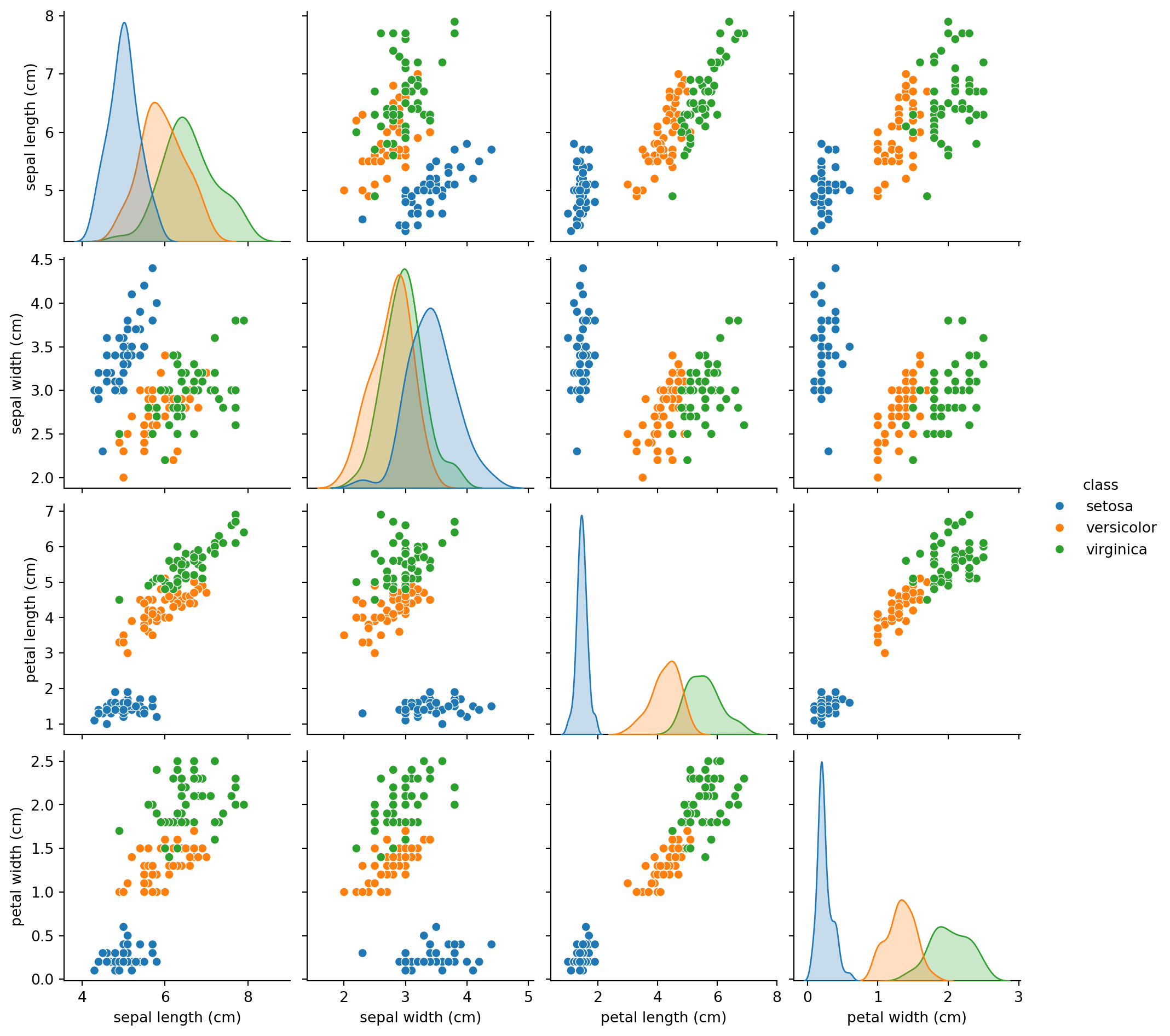
= 'auto' , hue= 'class' )
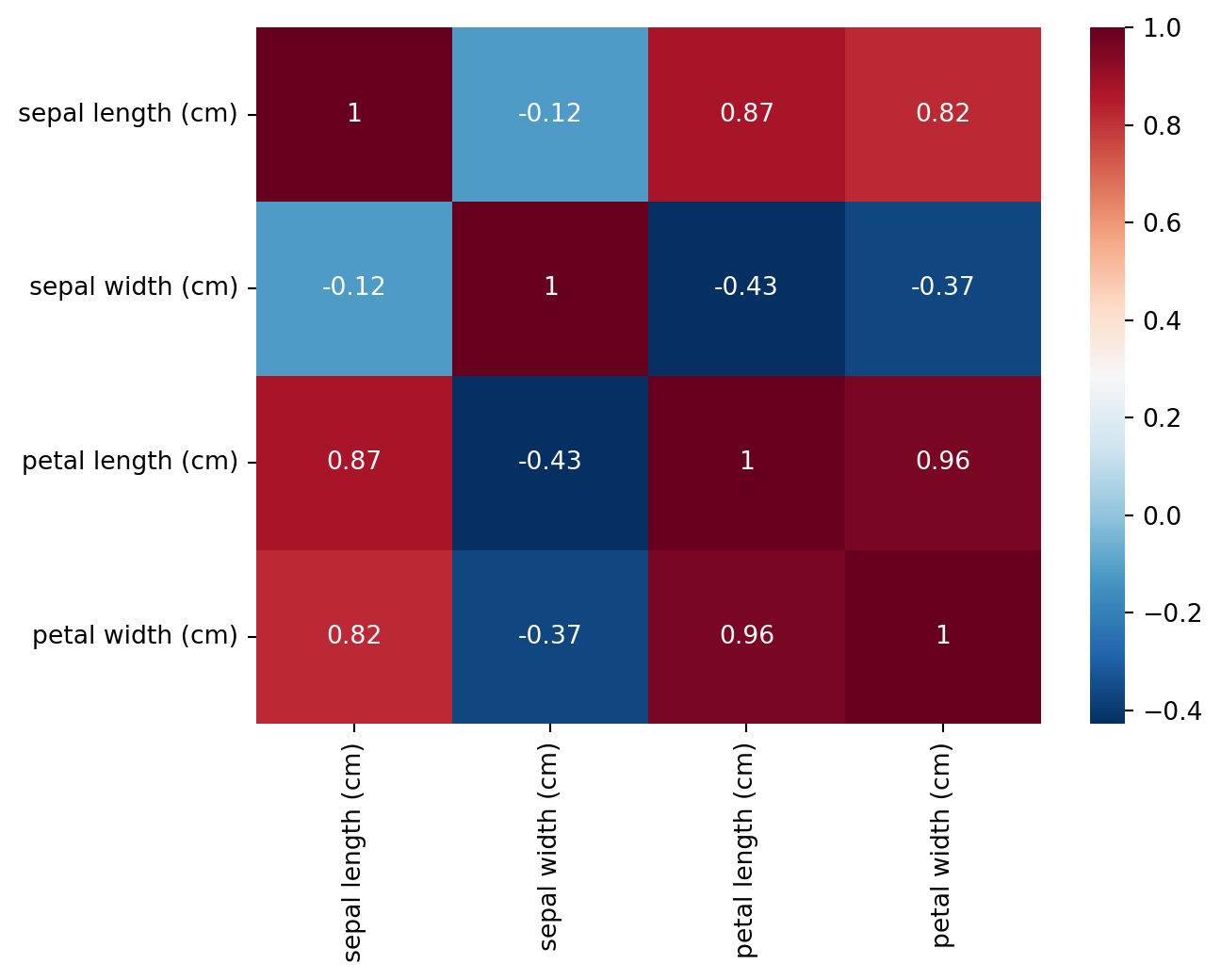
상관계수 행렬 그래프
= iris.drop(columns= 'class' ).corr(method= 'pearson' )= iris_corr.columns, yticklabels= iris_corr.columns, cmap= "RdBu_r" , annot= True )
Pandas Profiling
# from pandas_profiling import ProfileReport # # ProfileReport(iris)