import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
dataset = pd.read_csv('_data/14.csv')
x = dataset.iloc[:, [3, 4]].valuesk-means clustering
machine learning

K-means++ algorithm
- 시작점을 잘 선택하여 수렴 속도를 높이는 알고리즘
- 초기 중심점을 선택할 때, 멀리 떨어진 중심점을 선택하도록 함
- 첫 번째 중심점을 랜덤하게 선택
- 나머지 중심점을 선택할 때, 각 데이터 포인트와 가장 먼 중심점을 선택
- k개의 중심점을 선택할 때까지 반복
preprocessing
Modeling
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
cluster = KMeans(n_clusters=i, init='k-means++')
cluster.fit(x)
wcss.append(cluster.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of Cluster')
plt.ylabel('WCSS')
plt.show()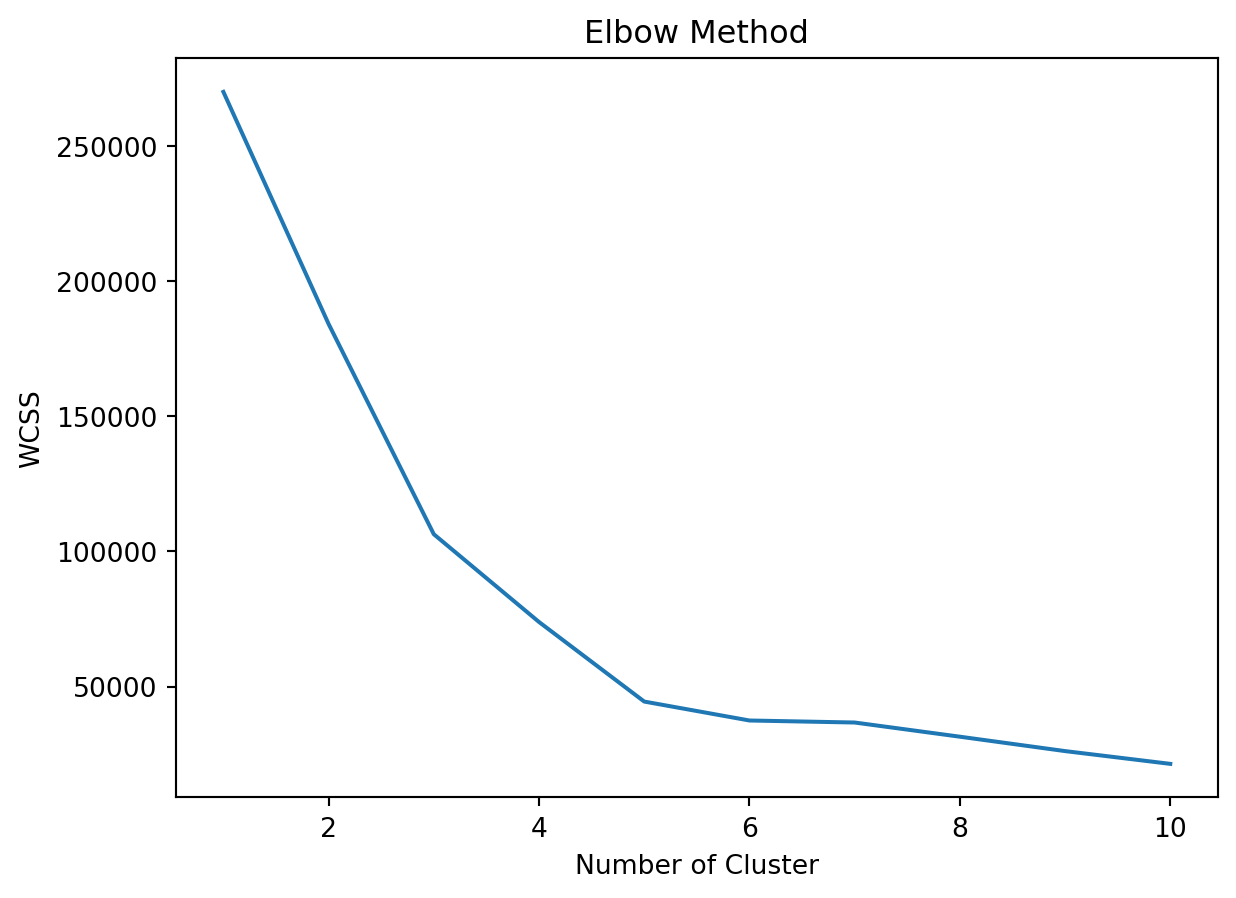
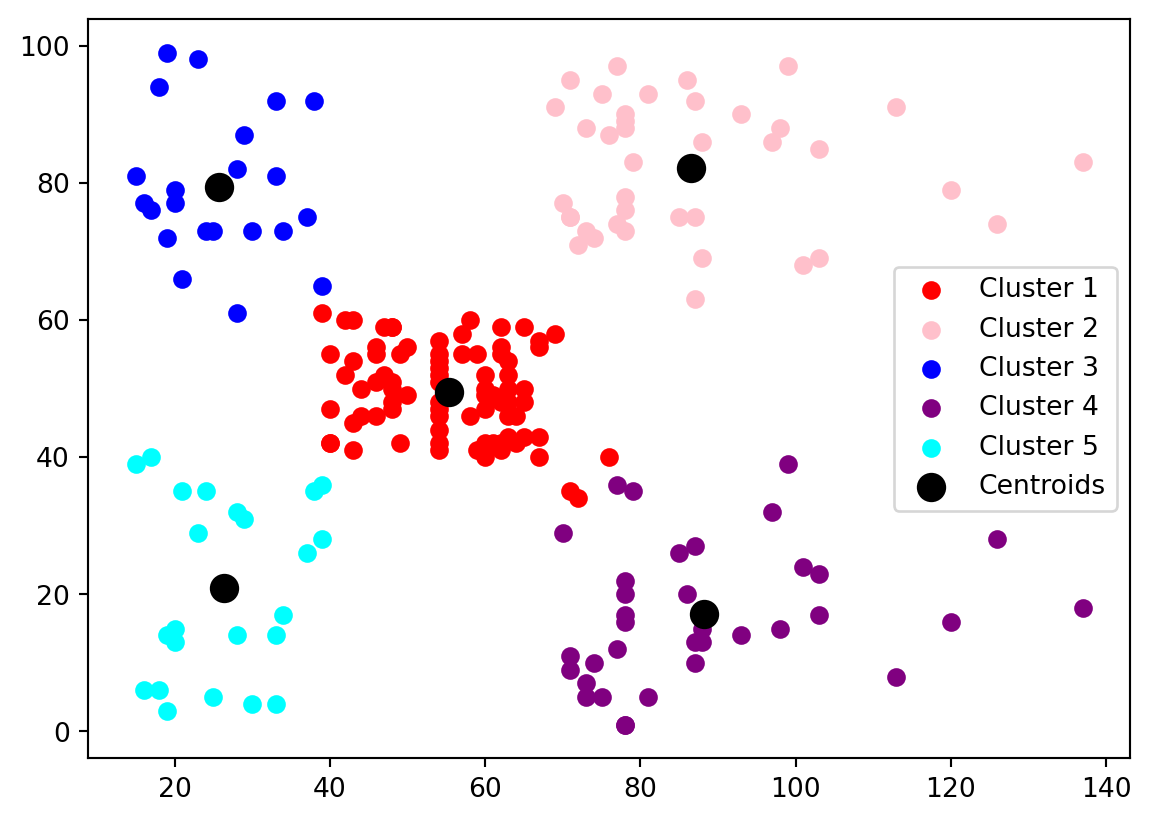
cluster = KMeans(n_clusters=5, init='k-means++')
y_kmeans = cluster.fit_predict(x)Visualize
plt.scatter(x[y_kmeans == 0, 0], x[y_kmeans == 0, 1], c='red', label='Cluster 1')
plt.scatter(x[y_kmeans == 1, 0], x[y_kmeans == 1, 1], c='pink', label='Cluster 2')
plt.scatter(x[y_kmeans == 2, 0], x[y_kmeans == 2, 1], c='blue', label='Cluster 3')
plt.scatter(x[y_kmeans == 3, 0], x[y_kmeans == 3, 1], c='purple', label='Cluster 4')
plt.scatter(x[y_kmeans == 4, 0], x[y_kmeans == 4, 1], c='cyan', label='Cluster 5')
plt.scatter(cluster.cluster_centers_[:, 0], cluster.cluster_centers_[:, 1], s=100, c='black', label='Centroids')
plt.legend()
plt.show()