2 - 데이터 처리 프로세스
adp

ETL
1. ETL 개요
ETL(Extract, Transformation, Load): 데이터 이동 및 변환 절차batch ETL,real-time ETL으로 나뉨
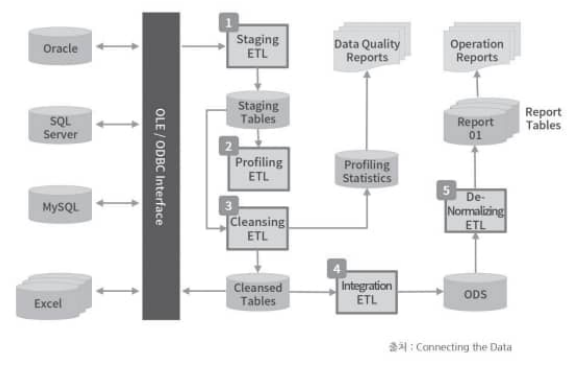
Interface: 다양한 소스로부터 데이터 휙득을 위한 인터페이스(OLEDB, ODBC, FTP)Staging: 정기적으로 데이터 원천으로 부터 저장. 아직은 정규화 xProfiling: staging table의 데이터 특성을 식별하고, 품질 측정Cleansing: profiling된 데이터를 보정Integration: 데이터 충돌을 해소하고, 데이터를 통합. 아마 여기서 정규화가 이루어질듯(왜 책에 설명 똑바로 안해놓지)Export: 운영보고서 생성, 데이터웨어하우스 / 데이터마트에 적재하기 위한 최적화(denormalization) 진행
2. ODS 구성
- 통합된 데이터를 저정하는 중간 저장소
실시간,거의 실시간으로 데이터 적재
3. 데이터 웨어하우스
- ODS를 통해 정제 / 통합된 데이터를 분석 및 보고서 생성을 위해 저장
특징
주제중심성영속성/비휘발성통합성시계열성
모델링 기법
스타 스키마(조인 스키마)- 제 3정규형의 fact 테이블과 제 2정규형의 차원 테이블로 구성
- 복잡성이 낮지만, 데이터 무결성이 떨어짐
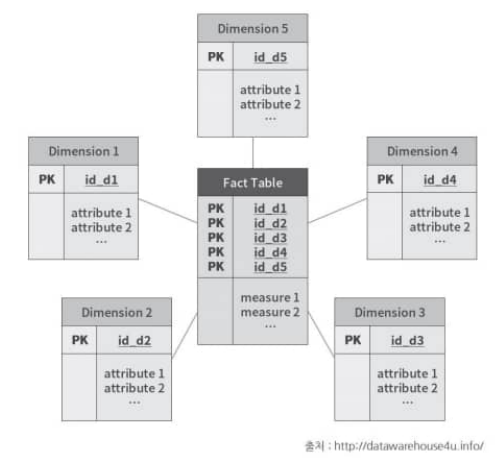
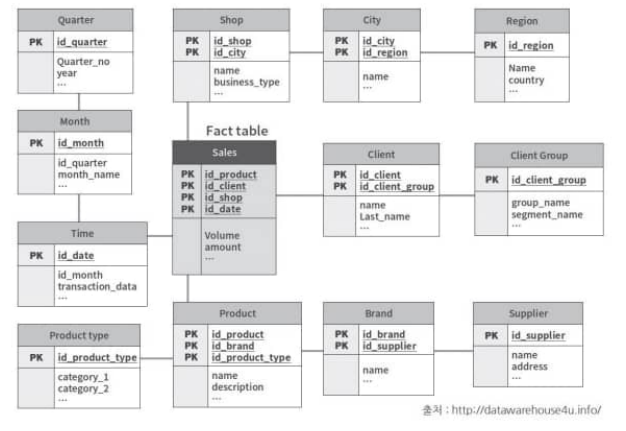
스노우플레이크 스키마- 스타 스키마의 차원 테이블을 제 3정규형으로 정규화한 상태
- 데이터 무결성이 높지만, 복잡성이 높음
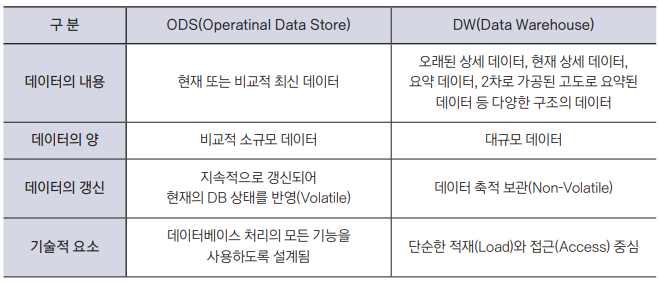
4. ODS vs DW
CDC(change data capture)
1. CDC 개념 및 특징
- 데이터 변경을 감지하고, 변경된 데이터를 추출하는 기술
- 하드웨어 계층부터 어플리케이션 계층까지 다양한 수준에서 적용 가능
2. CDC 구현 기법
Time Stamp on RowsVersion Numbers on Rows: 참조테이블을 같이 사용하는게 일반적이라고 한다.Status on Rows: time stamp, version number 보완 용도로, 사람이 레코드 반영 여부를 직접 판단할 수 있게 적용할 수 있음Time/Version/Status on RowsTriggers on Tables: message queue로 변경 발생시 subscribe 된 대상에 publish하는 방식. 시스템 관리 복잡도가 높아짐Event Programming: 어플리케이션에 데이터 변경 식별 기능을 추가Log Scanner on Database: 데이터 스키마 변경 불필요, 어플리케이션 영향 최소화, 지연시간 최소화
3. CDC 구현 방식
Push: 데이터 원천에서 변경 식별(agent)Pull: 대상 시스템에서 원천을 주기적으로 모니터링
EAI
1. EAI의 개념 및 특징
- 기업 내 혹은 기업 간 정보시스템을 연계하여 동기화.
- ETL은
batch 처리중심, EAI는실시간 혹은 근접 실시간 처리중심
2. 데이터 연계 방식
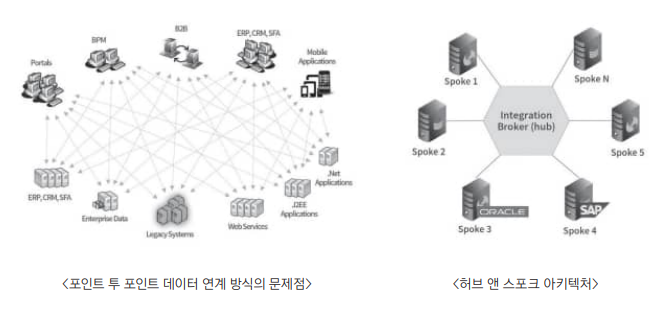
- ETL/CDC는 운영 데이터와 분석을 위한 데이터베이스가
구분되지만, EAI는그냥 통합
3. EAI 구성요소
Adapter: 시스템 간 데이터 변환Broker: 데이터 전송Bus: 데이터 전송 경로 설정Transformer: 데이터 형식 변환
4. EAI 구현 유형
Mediation: Publish/Subscribe 방식Federaion: Request/Reply 방식
5. EAI 활용 효과
- 협력사, 파트너, 고객과의 상호 협력 프로세스 연계
- 그룹 및 지주 회사 계열사들 간 상호 관련 데이터 동기화 등을 위한 데이터 표준화 기반 제공
6. EAI vs ESB
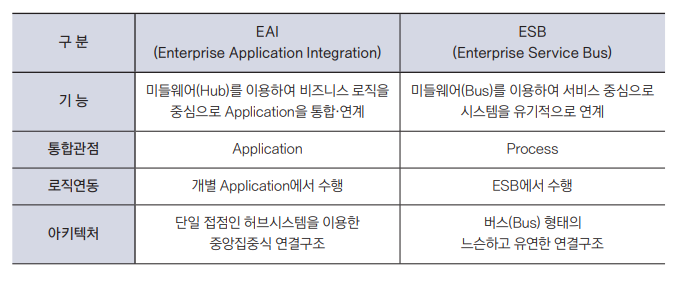
데이터 통합 및 연계 기법
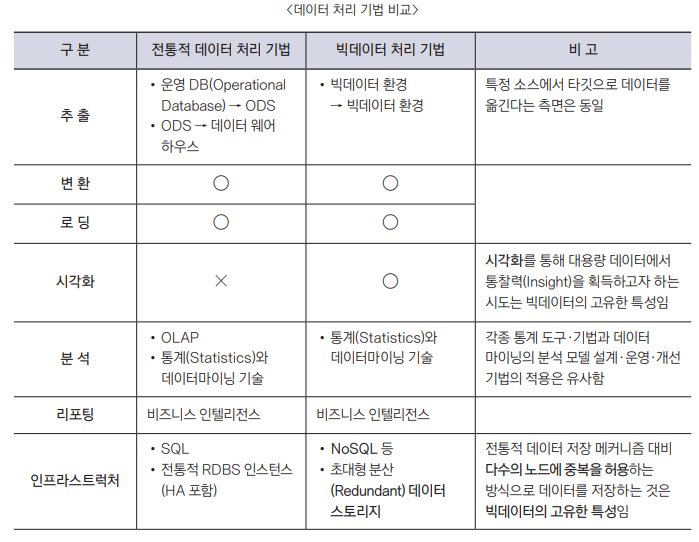
- 빅데이터는 시각화도 하고, NoSQL 같은 환경에서도 사용한다.
대용량의 비정형 데이터 처리 방법
2. 대규모 분산 병렬 처리
하둡:MapReduce와HDFS를 기반으로 한 분산 병렬 처리 프레임워크비공유 분산 아키텍쳐- 선형적인 성능과 용량 확장
- MapReduce failover
Hadoop ecosystem
3. 데이터 연동
대규모 연산을 데이터베이스에서 처리하기 어렵기 때문에, 하둡으로 복사해와서 MapReduce 연산 후, 결과를 다시 데이터베이스에 기록하기 위해 스쿱 사용
Sqoop- JDBC를 지원하는 RDBMS, Hbase와 Hadoop 간 데이터 전송(Import, Export)
- SQL 질의로 데이터 추출
- MapReduce 사용
4. 데이터 질의 기술
Hive: SQL과 유사한 HiveQL 질의, batch 처리SQL on Hadoop: SQL 질의, 실시간 처리- apache Drill, Stinger, Shark, Tajo, Impala, HAWQ, Presto