SQLqueries -S3as data source - supportsCSV,JSON,Parquet,ORCdata formats - 5$ per TB scanned ## Performance Improvement - usecolumnardata formats (less scan) =>Parquet,ORCby usingAWS Glue- compress data =>GZIP,Snappy,LZO-partition datasetsin S3 for easy querying on virtual columns (path) -Use larger files` (> 128MB) to minimize overhead
Federated Query
allows you to query data in relational, non-relational, object, … in a single query on AWS or on-premises
Amazon Redshift
based on postgres, not used for OLTP but OLAP copies data from S3, DynamoDB, RDS, Kinesis, EMR, Data Pipeline, Glue, Redshift Spectrum
cluster
- leader node
- compute node
snapshots and DR
- Multi-AZ for some cluster
- snapshots are point-in-time backups in S3
- change is saved
- automate snapshot, manual snapshote
loading data into redshift
- Amazon Kinesis Data Firehose
- Amazon S3 copy
- EC2 instance JDBC driver
Redshift Spectrum
: query data directly in S3 without loading it into Redshift
Amazon openSearch Service
: managed Elasticsearch and Kibana service # Amazon EMR : managed Hadoop and Spark service # AWS Glue : managed serverless ETL service 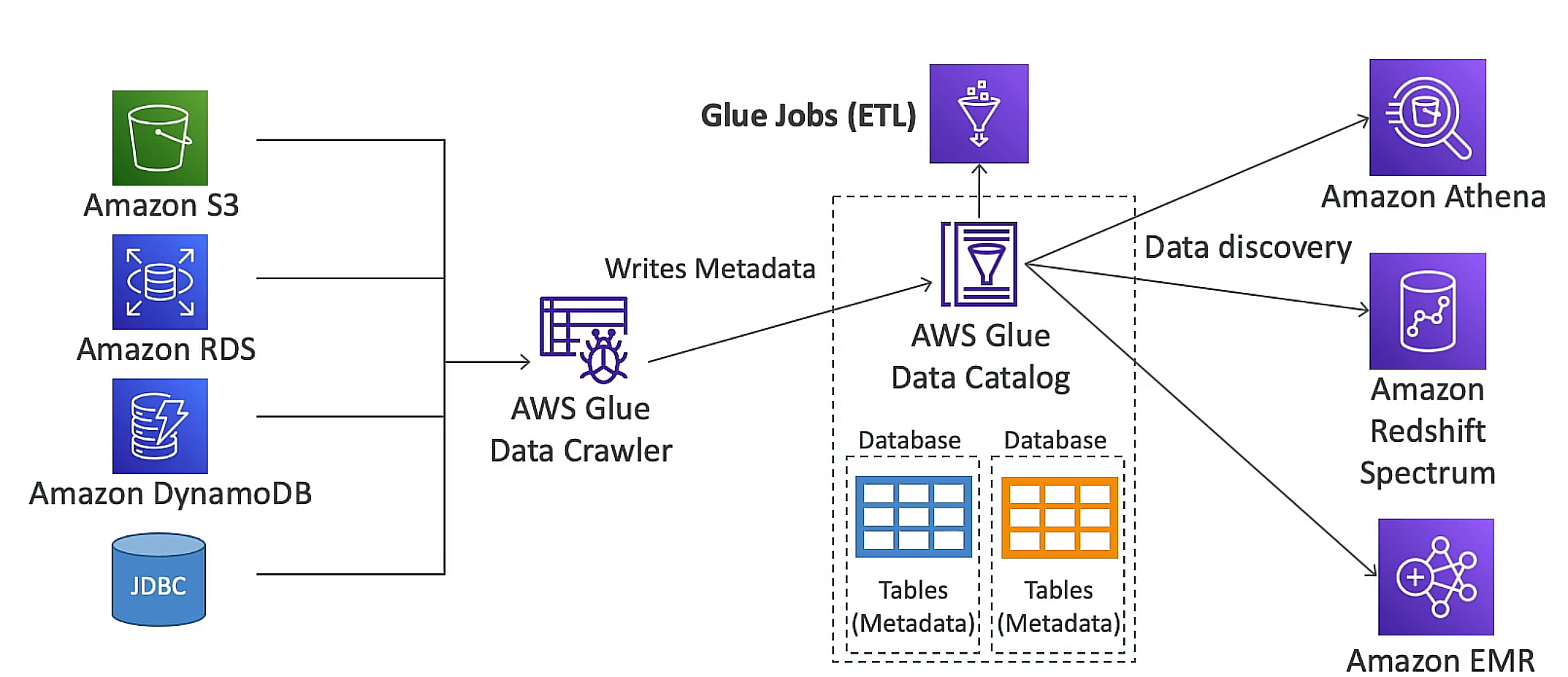
Kinesis
real-timedata streamingKinesis Data Streams:real-timedata streamingKinesis Data Firehose:loaddata intoS3,Redshift,ElasticSearch,SplunkKinesis Data Analytics:real-timedata analyticsKinesis Video Streams:real-timevideo streaming