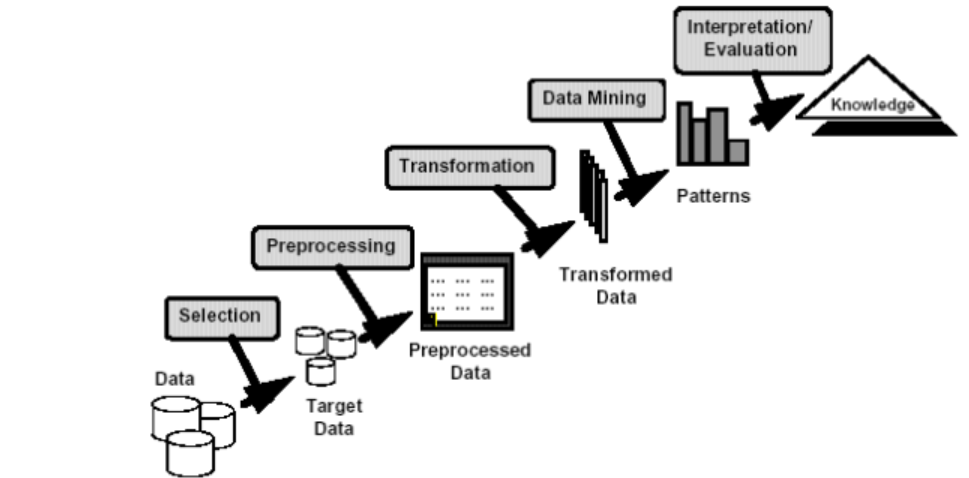
데이터 전처리
data mining

scaling
- min-max scaling: \(x' = \frac{x - min(x)}{max(x) - min(x)}\)
- 0과 1 사이의 값으로 변환
- standardization: \(x' = \frac{x - \mu}{\sigma}\), \(\mu\): 평균, \(\sigma\): 표준편차
Train Test Resampling
resampling
- resampling: 데이터를 여러 번 나누어 모델을 학습하고 평가하는 방법
- train set: 모델을 학습하는 데이터
- validation data set: 하이퍼파라미터를 튜닝
- test set: 모델의 성능 평가
- 층화추출법: stratified sampling
methods
- hold out method: data를 train set과 test set으로 나누는 방법
- 어떤 데이터가 train, test set에 포함되는지에 따라 결과가 달라질 수 있다.
- → train set과 test set을 여러 번 나누어 모델을 학습하고 평가하는 방법이 필요하다.
- cross validation: 데이터를 여러 번 나누어 모델을 학습하고 평가하는 방법
- k-fold cross validation: 데이터를 k개의 fold로 나누고, 각 fold를 test set으로 사용하여 모델을 학습하고 평가한다.
- random하게 sampling할 수 있고, 안할 수도 있음
- leave-one-out cross validation: 데이터의 개수가 n개일 때, n-1개의 데이터를 train set으로 사용하고 1개의 데이터를 test set으로 사용하는 방법
- error는 각 train set, fold 에서 계산된 error의 평균으로 구한다.
- k-fold cross validation: 데이터를 k개의 fold로 나누고, 각 fold를 test set으로 사용하여 모델을 학습하고 평가한다.
- bootstrap: 데이터를 중복을 허용하여 샘플링하는 방법
- 원본 데이터에서 n개의 데이터를 랜덤하게 선택하여 train set을 만들고, 나머지 데이터를 test set으로 사용한다.
- 여러 번 반복하여 모델을 학습하고 평가한다.
- 실제 오류 추정치의 편향과 분산 모두에 대한 정확한 측정값을 얻을 수 있다.