import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'Noto Sans KR'
df = pd.read_csv('_data/air.csv')계절성 고려
확률 통계
시계열 분석

SARIMA 모델
- \(SARIMA(p, d, q)(P, D, Q)_m\) 형태로 표현
- \(m\): 계절성 주기
- \(P, D, Q\): 계절성 AR, 차분, MA 차수
from statsmodels.tsa.seasonal import STL
decomposition = STL(df['Passengers'], period=12).fit()
decomposition.plot()
plt.show()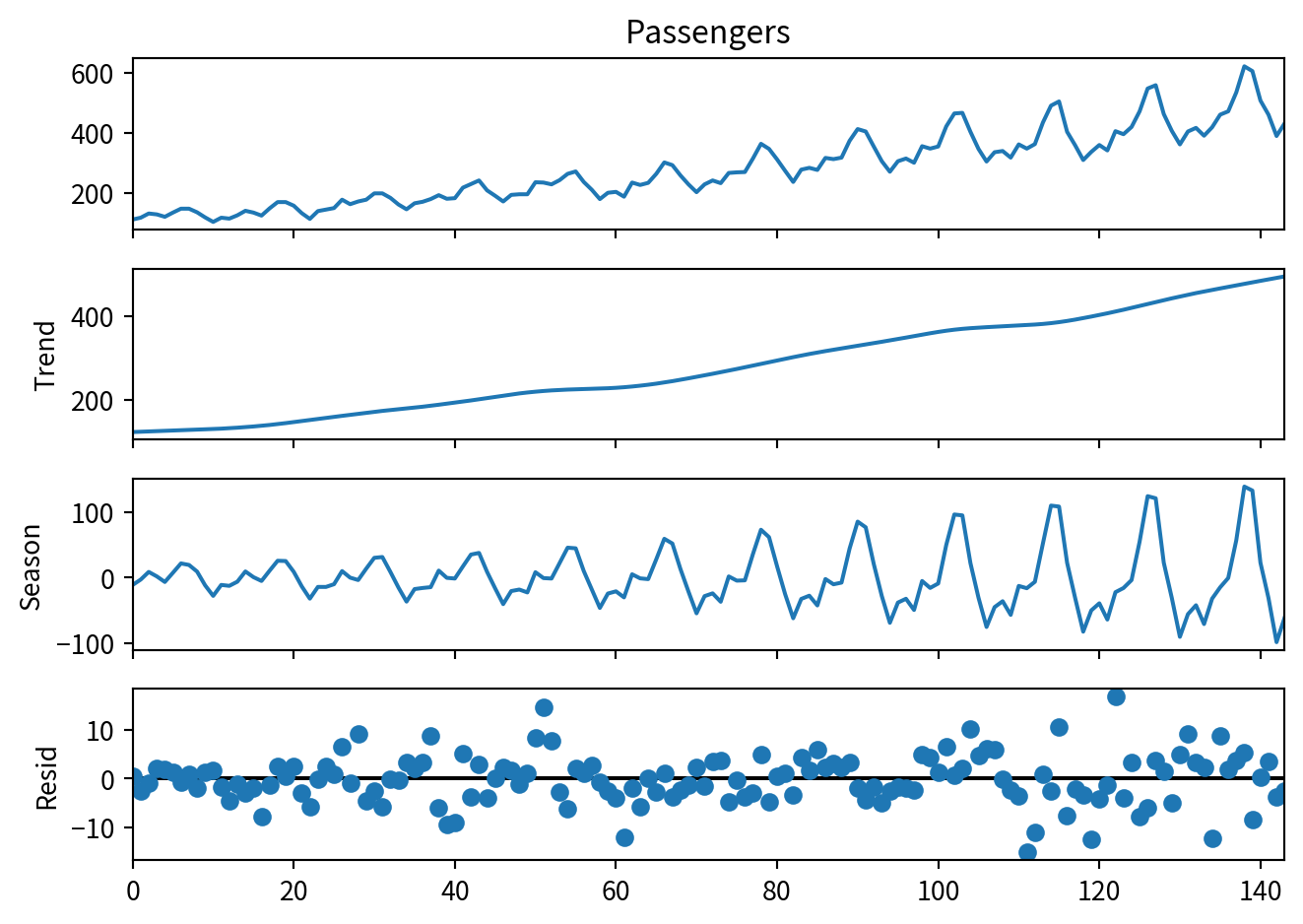
from statsmodels.tsa.stattools import adfuller
df_diff = np.diff(df['Passengers'], n=1)
ADF_result = adfuller(df_diff)
ADF_result[0], ADF_result[1](np.float64(-2.8292668241700047), np.float64(0.05421329028382478))df_diff = np.diff(df_diff, n=12)
ADF_result = adfuller(df_diff)
ADF_result[0], ADF_result[1](np.float64(-17.62486236026156), np.float64(3.823046855601547e-30))from typing import Union
from statsmodels.tsa.statespace.sarimax import SARIMAX
def optimize_SARIMA(endog: Union[pd.Series, list], order_list: list, d: int, D: int, s: int) -> pd.DataFrame:
results = []
for order in order_list:
try:
model = SARIMAX(endog,
order=(order[0], d, order[1]),
seasonal_order=(order[2], D, order[3], s),
simple_differencing=False).fit(disp=False)
except:
continue
aic = model.aic
results.append([order, aic])
result_df = pd.DataFrame(results)
result_df.columns = ['(p, q, P, Q)', 'AIC']
result_df = result_df.sort_values(by="AIC").reset_index(drop=True)
return result_dffrom itertools import product
train = df.iloc[:-12]['Passengers']
test = df.iloc[-12:]
# ps = range(0, 4, 1)
# qs = range(0, 4, 1)
# Ps = range(0, 4, 1)
# Qs = range(0, 4, 1)
#
# SARIMA_order_list = list(product(ps, qs, Ps, Qs))
#
#
# d = 1
# D = 1
# s = 12
# SARIMA_result_df = optimize_SARIMA(train, SARIMA_order_list, d, D, s)
# SARIMA_result_dfSARIMA_model = SARIMAX(train, order=(2, 1, 1), seasonal_order=(1, 1, 2, 12), simple_differencing=False)
SARIMA_model_fit = SARIMA_model.fit(disp=False)
SARIMA_model_fit.plot_diagnostics(figsize=(10, 8))
plt.show()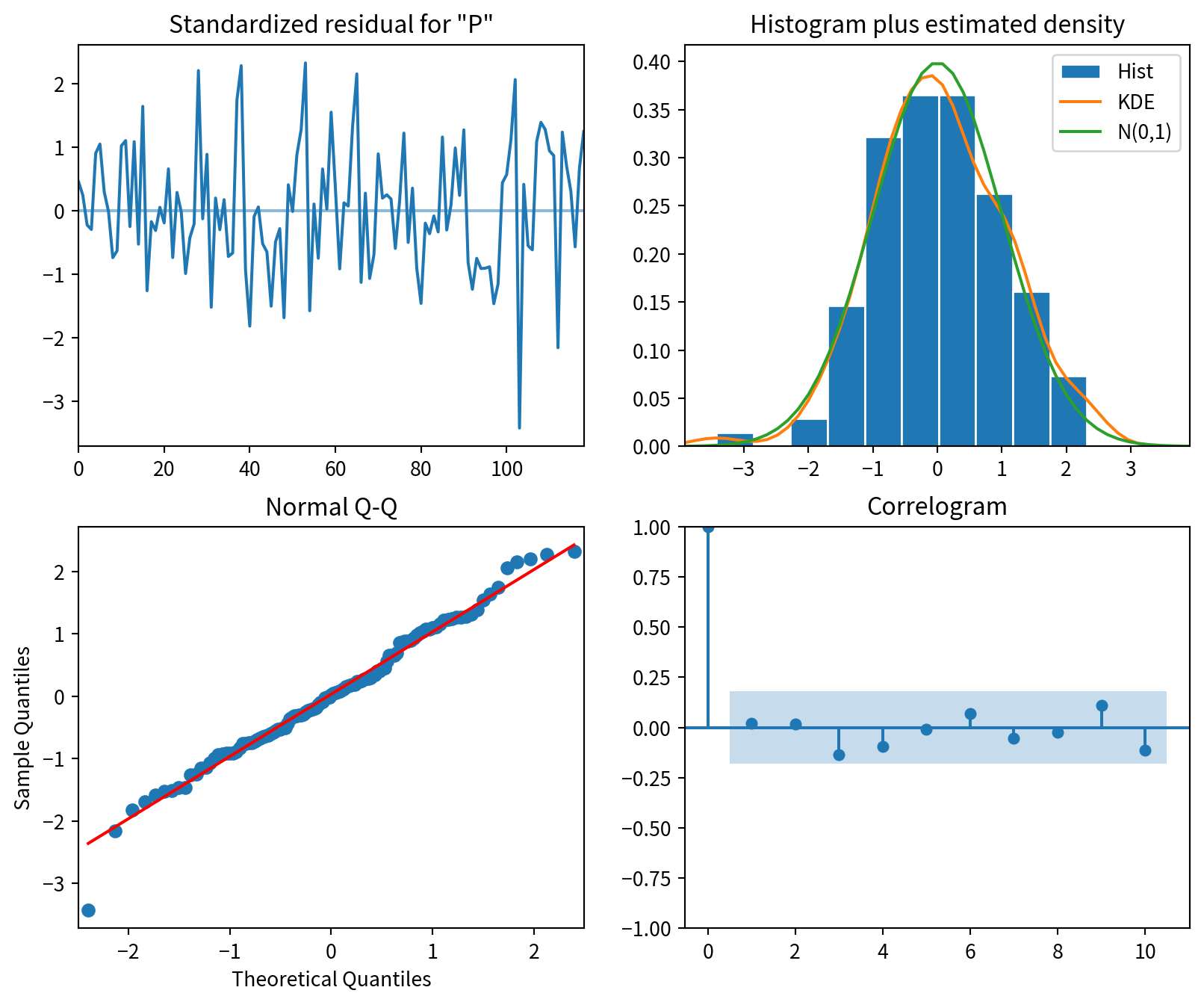
from statsmodels.stats.diagnostic import acorr_ljungbox
tr = acorr_ljungbox(SARIMA_model_fit.resid, np.arange(1, 11))
tr| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 0.004688 | 0.945412 |
| 2 | 0.743919 | 0.689382 |
| 3 | 1.018359 | 0.796810 |
| 4 | 1.223784 | 0.874167 |
| 5 | 1.435211 | 0.920423 |
| 6 | 1.710187 | 0.944332 |
| 7 | 2.304834 | 0.941063 |
| 8 | 2.715298 | 0.950935 |
| 9 | 2.731198 | 0.974006 |
| 10 | 4.968094 | 0.893299 |
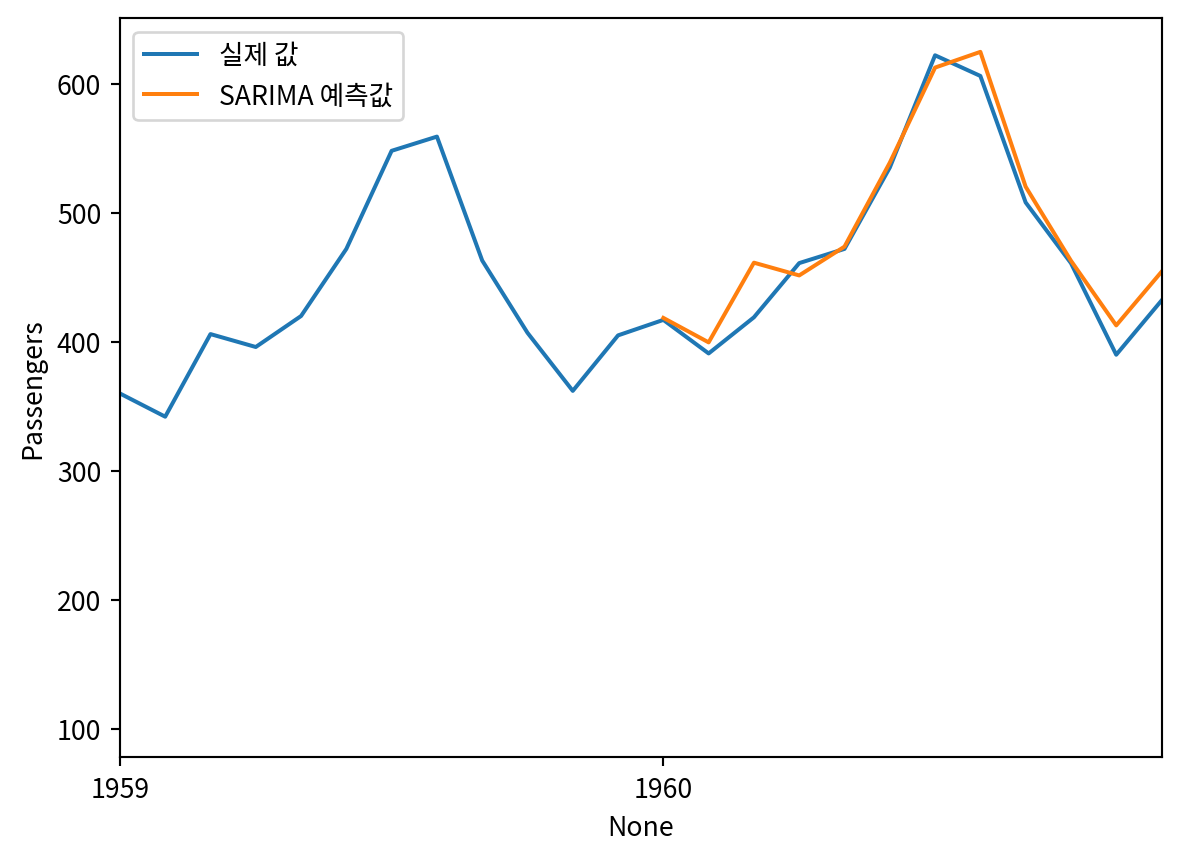
SARIMA_pred = SARIMA_model_fit.get_prediction(132, 143).predicted_mean
test['SARIMA_pred'] = SARIMA_pred
sns.lineplot(data=df, x=df.index, y='Passengers', label='실제 값')
sns.lineplot(data=test, x=test.index, y='SARIMA_pred', label='SARIMA 예측값')
plt.xticks(np.arange(0, 145, 12), np.arange(1949, 1962, 1))
plt.xlim(120, 143)