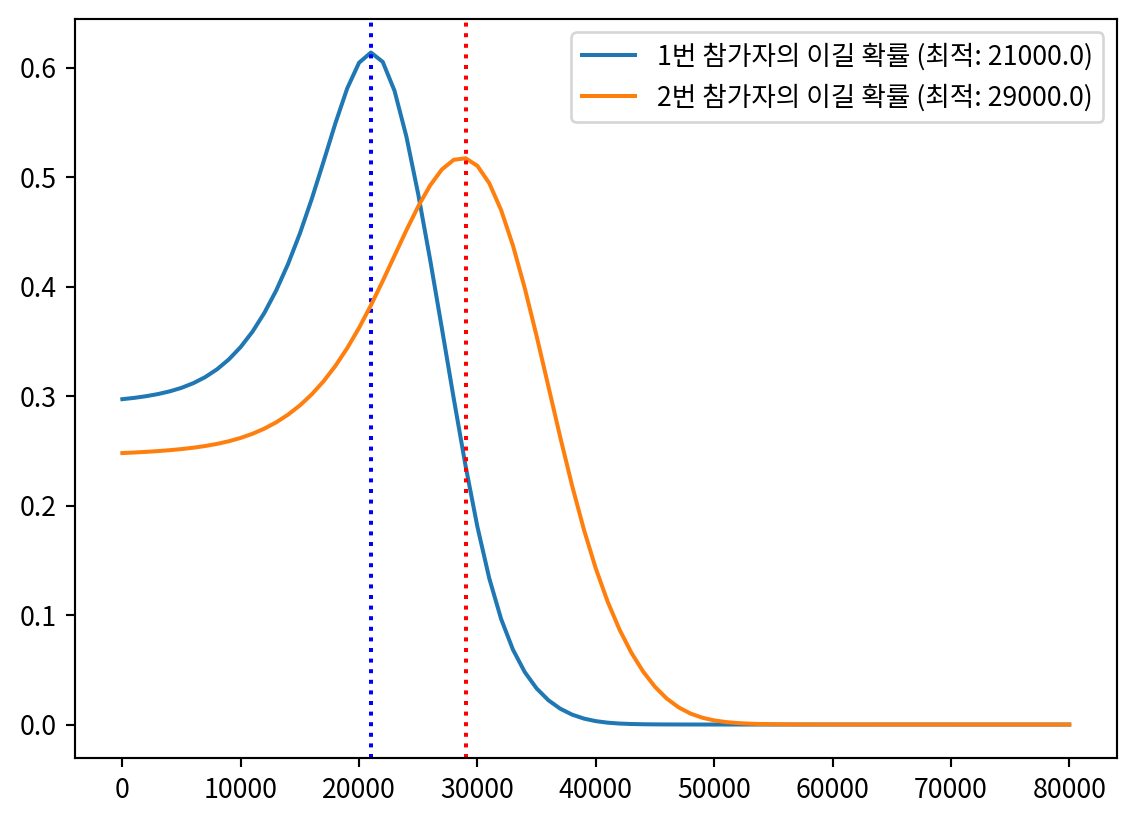
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Noto Sans KR'
df1 = pd.read_csv('https://raw.githubusercontent.com/AllenDowney/ThinkBayes2/master/data/showcases.2011.csv', index_col=0, skiprows=[1]).dropna().transpose()
df2 = pd.read_csv('https://raw.githubusercontent.com/AllenDowney/ThinkBayes2/master/data/showcases.2012.csv', index_col=0, skiprows=[1]).dropna().transpose()
df = pd.concat([df1, df2], ignore_index=True)
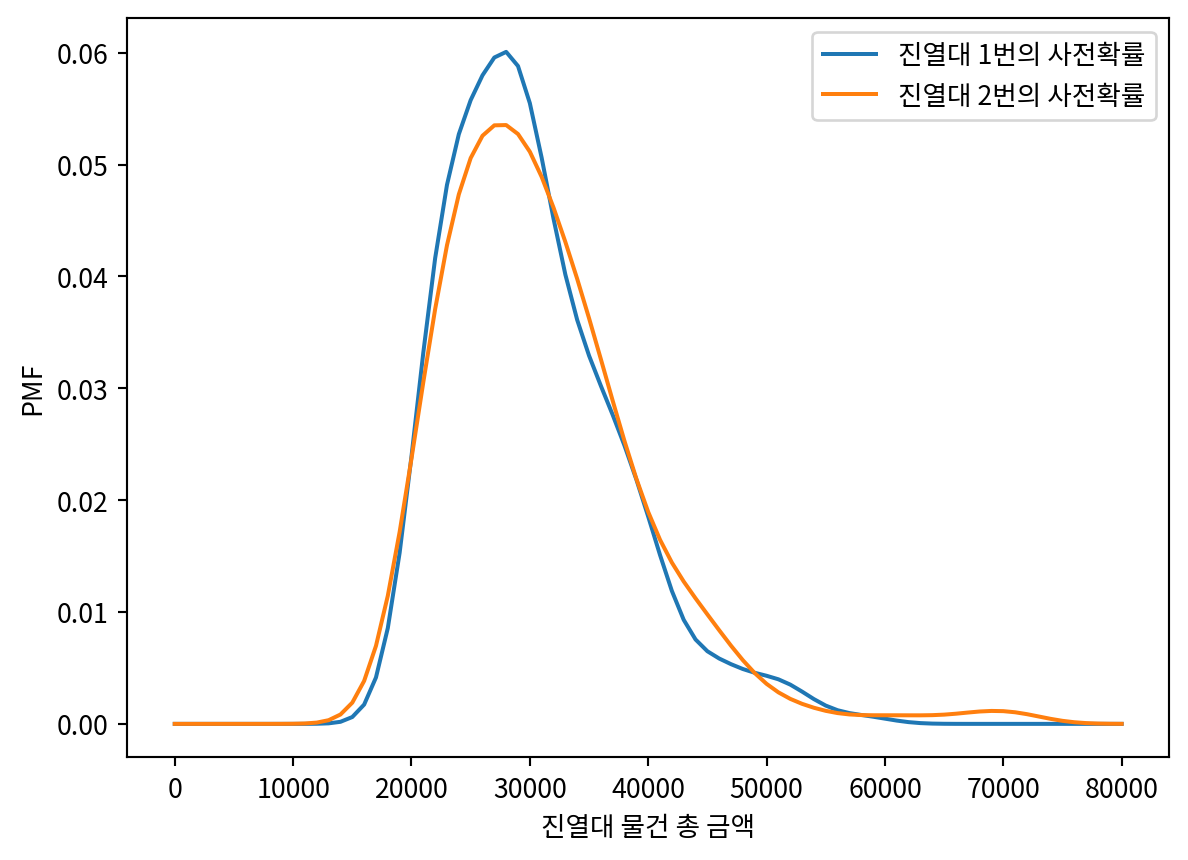
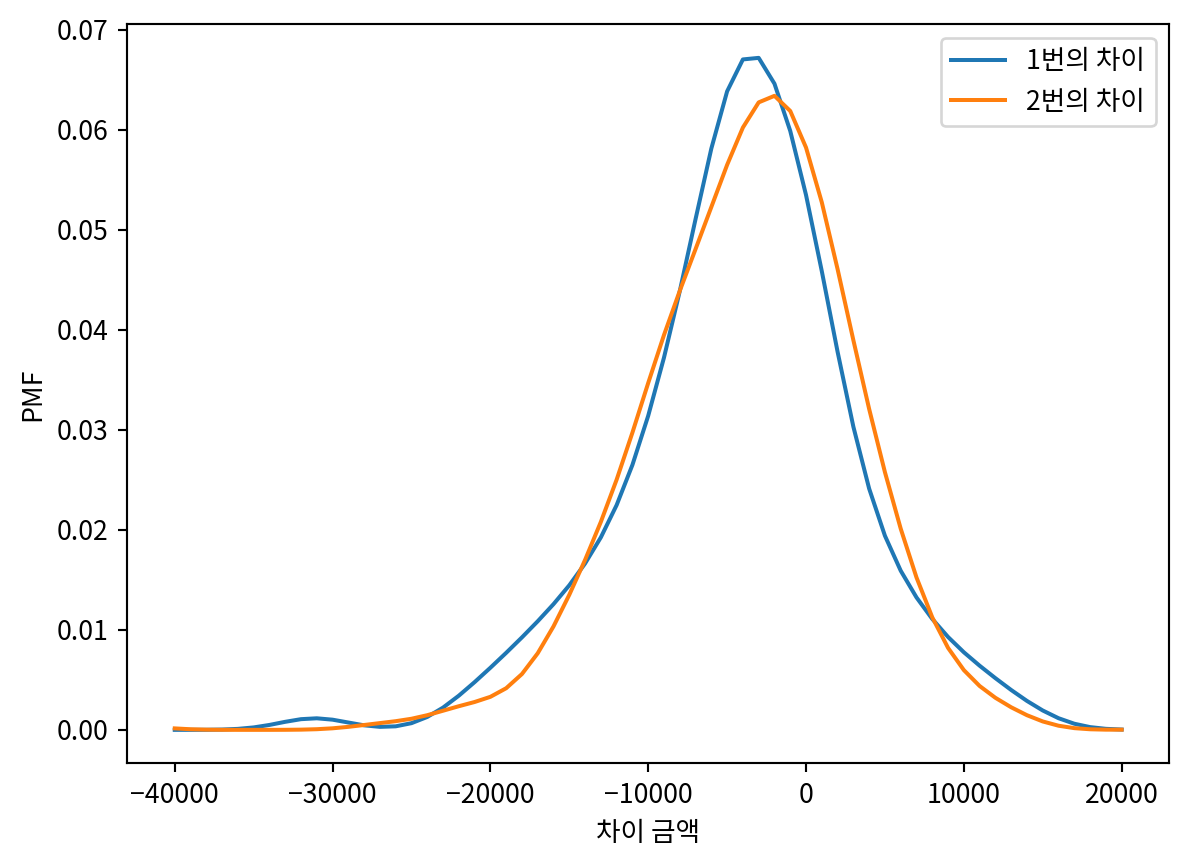
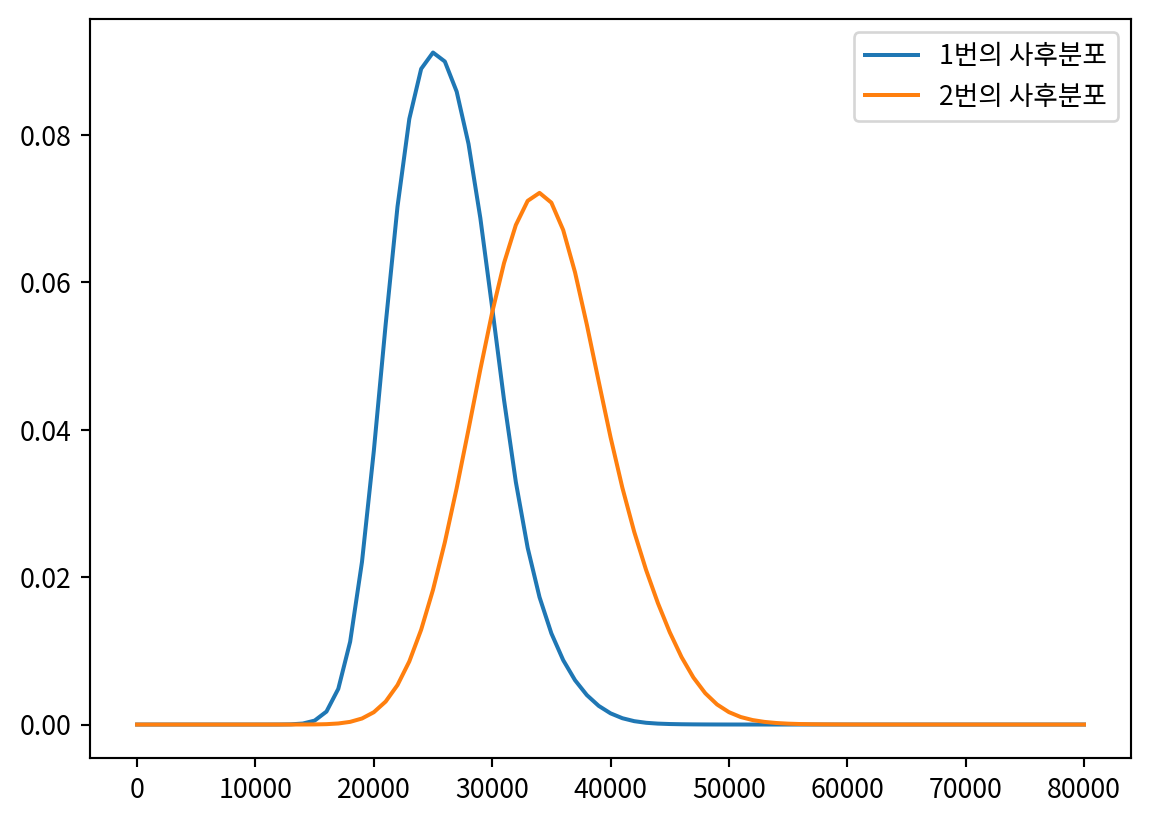
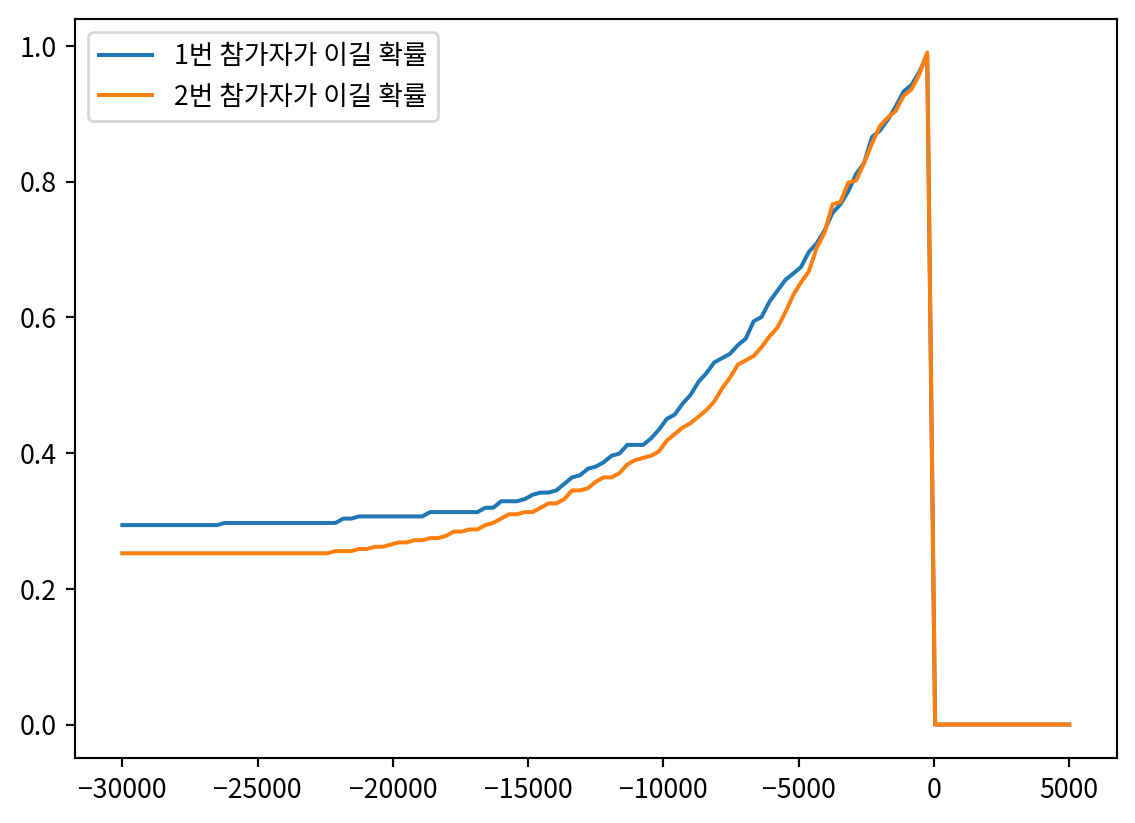
df| Showcase 1 | Showcase 2 | Bid 1 | Bid 2 | Difference 1 | Difference 2 | |
|---|---|---|---|---|---|---|
| 0 | 50969.0 | 45429.0 | 42000.0 | 34000.0 | 8969.0 | 11429.0 |
| 1 | 21901.0 | 34061.0 | 14000.0 | 59900.0 | 7901.0 | -25839.0 |
| 2 | 32815.0 | 53186.0 | 32000.0 | 45000.0 | 815.0 | 8186.0 |
| 3 | 44432.0 | 31428.0 | 27000.0 | 38000.0 | 17432.0 | -6572.0 |
| 4 | 24273.0 | 22320.0 | 18750.0 | 23000.0 | 5523.0 | -680.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 308 | 25375.0 | 31986.0 | 36000.0 | 32000.0 | -10625.0 | -14.0 |
| 309 | 24949.0 | 30696.0 | 20500.0 | 31000.0 | 4449.0 | -304.0 |
| 310 | 23662.0 | 22329.0 | 26000.0 | 20000.0 | -2338.0 | 2329.0 |
| 311 | 23704.0 | 34325.0 | 23800.0 | 34029.0 | -96.0 | 296.0 |
| 312 | 20898.0 | 23876.0 | 28000.0 | 25000.0 | -7102.0 | -1124.0 |
313 rows × 6 columns