import numpy as np
from empiricaldist import Pmf
n = 10000
a = np.random.randint(1, 7, size=(n, 4))
a.sort(axis=1)
t = a[:, 1:].sum(axis=1)
pmf_best3 = Pmf.from_seq(t)최솟값, 최댓값 그리고 혼합 분포
확률 통계

넷 중 높은 값
연습문제
7-1
n = 10000
a = np.random.randint(1, 7, size=(n, 4))
a.sort(axis=1)
t = a[:, 1:].sum(axis=1)
pmf_best3 = Pmf.from_seq(t)
cdf_best3 = pmf_best3.make_cdf()from empiricaldist import Cdf
import matplotlib.pyplot as plt
standard = [15,14,13,12,10,8]
standard_pmf = Pmf.from_seq(standard)
cdf_best3.plot(label='best 3 of 4', color='C1', ls='--')
cdf_standard = Cdf.from_seq(standard)
cdf_standard.step(label='standard set', color='C7')
plt.ylabel('CDF');
cdf_max_dist6 = cdf_best3.max_dist(6)
cdf_min_dist6 = cdf_best3.min_dist(6)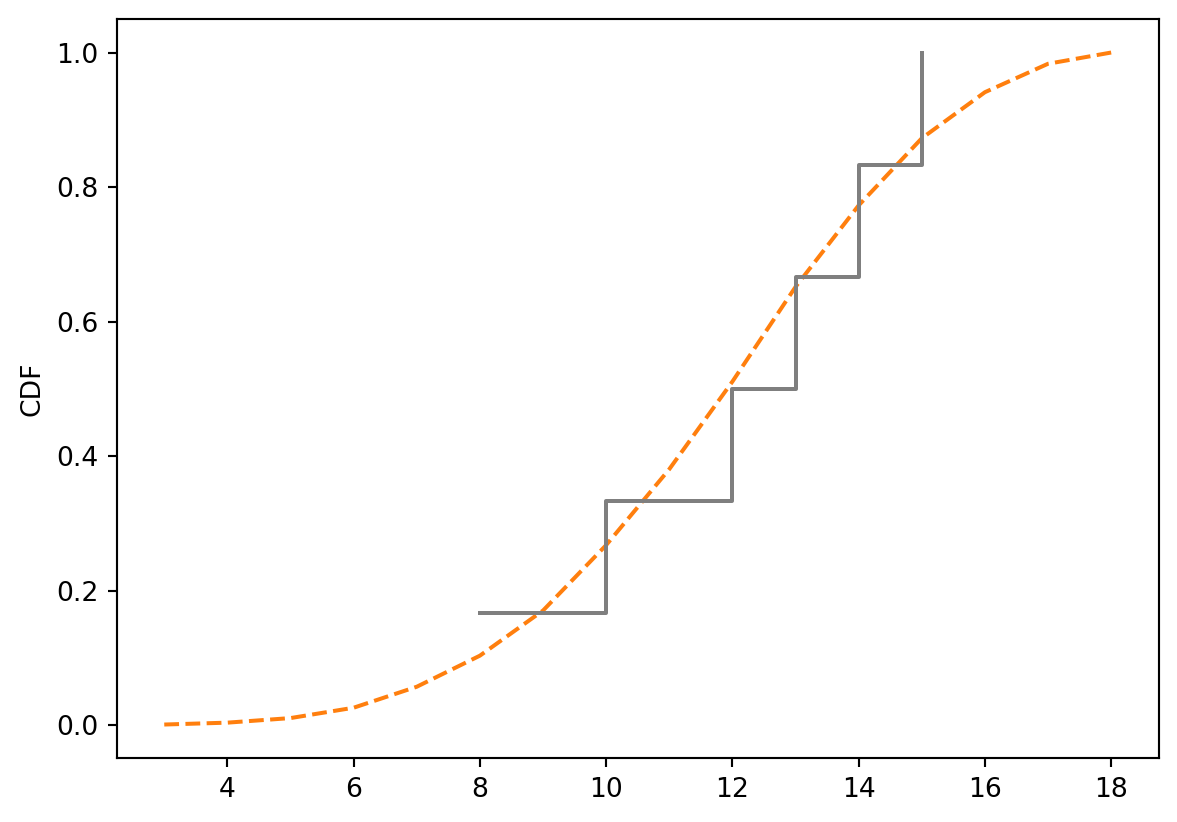
print(f"Best 3 of 4 - 평균: {pmf_best3.mean():.2f}, 표준편차: {pmf_best3.std():.2f}")
print(f"Standard array - 평균: {standard_pmf.mean():.2f}, 표준편차: {standard_pmf.std():.2f}")
prob_less_than_8 = cdf_best3(7)
print(f"Best 3 of 4에서 8보다 작은 값이 나올 확률: {prob_less_than_8:.4f}")
print(f"6번 굴렸을 때 최소 하나가 8보다 작을 확률: {(1 - cdf_min_dist6(8)):.4f}")
prob_greater_than_15 = 1 - cdf_best3(15)
print(f"Best 3 of 4에서 15보다 큰 값이 나올 확률: {prob_greater_than_15:.4f}")
print(f"6번 굴렸을 때 최소 하나가 15보다 클 확률: {(1 - cdf_max_dist6(15)):.4f}")Best 3 of 4 - 평균: 12.25, 표준편차: 2.82
Standard array - 평균: 12.00, 표준편차: 2.38
Best 3 of 4에서 8보다 작은 값이 나올 확률: 0.0569
6번 굴렸을 때 최소 하나가 8보다 작을 확률: 0.5206
Best 3 of 4에서 15보다 큰 값이 나올 확률: 0.1275
6번 굴렸을 때 최소 하나가 15보다 클 확률: 0.55887-2
def update_dice(pmf, data):
hypos = pmf.qs
likelihood = 1 / hypos
likelihood[data > hypos] = 0
pmf *= likelihood
pmf.normalize()
pmf = Pmf.from_seq([6, 8, 10])
update_dice(pmf, 1)
pmf| probs | |
|---|---|
| 6 | 0.425532 |
| 8 | 0.319149 |
| 10 | 0.255319 |
import pandas as pd
def make_mixture(pmf, pmf_seq):
df = pd.DataFrame(pmf_seq).fillna(0).transpose()
df *= np.array(pmf)
total = df.sum(axis=1)
return Pmf(total)
pmf_6 = Pmf.from_seq(range(1, 7)) # 6면체 주사위
pmf_8 = Pmf.from_seq(range(1, 9)) # 8면체 주사위
pmf_10 = Pmf.from_seq(range(1, 11)) # 10면체 주사위
mixture = make_mixture(pmf, [pmf_6, pmf_8, pmf_10])
prob_6_damage = mixture[6] if 6 in mixture.qs else 0
print(f"\nProbability of 6 points of damage: {prob_6_damage:.4f}")
Probability of 6 points of damage: 0.13637-3
mean = 950
std = 50
sample = np.random.normal(mean, std, size=365)
pmf = Pmf.from_seq(sample)
cdf = pmf.make_cdf()means = []
n_values = np.arange(1, 20)
for n in n_values:
cdf_max_dist = cdf.max_dist(n)
mean_max = cdf_max_dist.mean()
means.append(mean_max)
means = np.array(means)
target = 1000
closest_idx = np.argmin(np.abs(means - target))
optimal_n = n_values[closest_idx]
closest_mean = means[closest_idx]
print(f"\n결과:")
print(f"1000g에 가장 가까운 평균을 만드는 n: {optimal_n}")
print(f"해당 n에서의 평균: {closest_mean:.2f}g")
print(f"목표값과의 차이: {abs(closest_mean - target):.2f}g")
결과:
1000g에 가장 가까운 평균을 만드는 n: 3
해당 n에서의 평균: 997.51g
목표값과의 차이: 2.49g