import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.family'] = 'Noto Sans KR'
train = pd.read_csv('_data/train.csv', index_col=0)
test_X = pd.read_csv('_data/test.csv', index_col=0)
train_X = train.drop('Survived', axis=1)
train_y = train.iloc[:, 0]Titanic
확률 통계

Preprocessing
Data load
결측치 처리
train_X.info(), test_X.info()<class 'pandas.core.frame.DataFrame'>
Index: 891 entries, 1 to 891
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 891 non-null int64
1 Name 891 non-null object
2 Sex 891 non-null object
3 Age 714 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Ticket 891 non-null object
7 Fare 891 non-null float64
8 Cabin 204 non-null object
9 Embarked 889 non-null object
dtypes: float64(2), int64(3), object(5)
memory usage: 76.6+ KB
<class 'pandas.core.frame.DataFrame'>
Index: 418 entries, 892 to 1309
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 418 non-null int64
1 Name 418 non-null object
2 Sex 418 non-null object
3 Age 332 non-null float64
4 SibSp 418 non-null int64
5 Parch 418 non-null int64
6 Ticket 418 non-null object
7 Fare 417 non-null float64
8 Cabin 91 non-null object
9 Embarked 418 non-null object
dtypes: float64(2), int64(3), object(5)
memory usage: 35.9+ KB(None, None)- 결측치가 있는 column은 Age, Cabin, Embarked, Fare
- Cabin은 너무 많으니까 걍 삭제하자
train_X.drop('Cabin', axis=1, inplace=True)
test_X.drop('Cabin', axis=1, inplace=True)- Age, Fare랑 Embarked는 일단 지워보자
train_X.dropna(subset=['Embarked', 'Age'], inplace=True)
test_X.dropna(subset=['Fare', 'Age'], inplace=True)
train_X.info(), test_X.info()<class 'pandas.core.frame.DataFrame'>
Index: 712 entries, 1 to 891
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 712 non-null int64
1 Name 712 non-null object
2 Sex 712 non-null object
3 Age 712 non-null float64
4 SibSp 712 non-null int64
5 Parch 712 non-null int64
6 Ticket 712 non-null object
7 Fare 712 non-null float64
8 Embarked 712 non-null object
dtypes: float64(2), int64(3), object(4)
memory usage: 55.6+ KB
<class 'pandas.core.frame.DataFrame'>
Index: 331 entries, 892 to 1307
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 331 non-null int64
1 Name 331 non-null object
2 Sex 331 non-null object
3 Age 331 non-null float64
4 SibSp 331 non-null int64
5 Parch 331 non-null int64
6 Ticket 331 non-null object
7 Fare 331 non-null float64
8 Embarked 331 non-null object
dtypes: float64(2), int64(3), object(4)
memory usage: 25.9+ KB(None, None)EDA
train_X.describe()| Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|
| count | 712.000000 | 712.000000 | 712.000000 | 712.000000 | 712.000000 |
| mean | 2.240169 | 29.642093 | 0.514045 | 0.432584 | 34.567251 |
| std | 0.836854 | 14.492933 | 0.930692 | 0.854181 | 52.938648 |
| min | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 1.000000 | 20.000000 | 0.000000 | 0.000000 | 8.050000 |
| 50% | 2.000000 | 28.000000 | 0.000000 | 0.000000 | 15.645850 |
| 75% | 3.000000 | 38.000000 | 1.000000 | 1.000000 | 33.000000 |
| max | 3.000000 | 80.000000 | 5.000000 | 6.000000 | 512.329200 |
- Pclass: 명목 1, 2, 3
- Sex: 명목 male, female
- Age: 연속형 (0.42~80)
- SibSp: 명목, 0, 1, 2, 3, 4, 5
- Parch: 명목, 0, 1, 2, 3, 4, 5, 6
- Ticket: 541개 짜리 명목
- Fare: 연속 (34.56~512.32)
- Embarked: 명목 S C Q
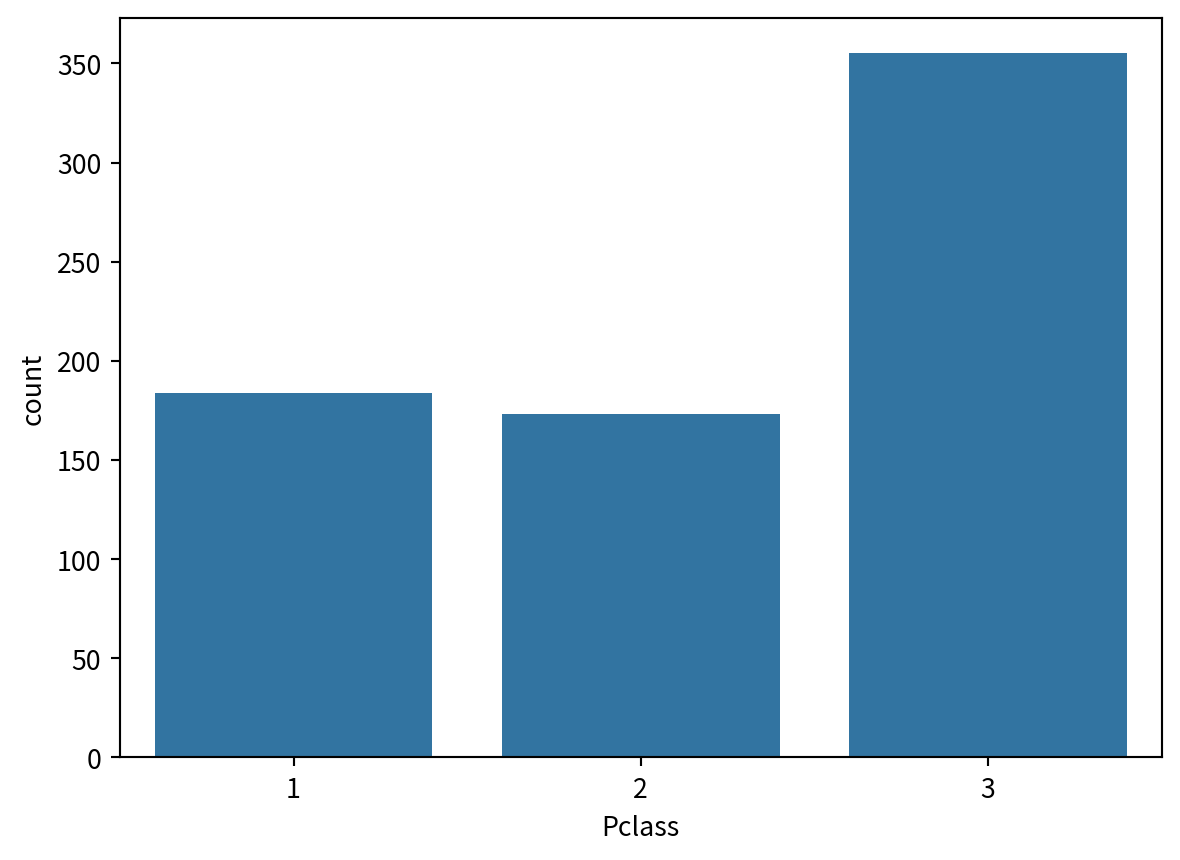
bindo = pd.DataFrame(train_X['Pclass'].value_counts())
sns.barplot(bindo, x="Pclass", y="count", legend=False)