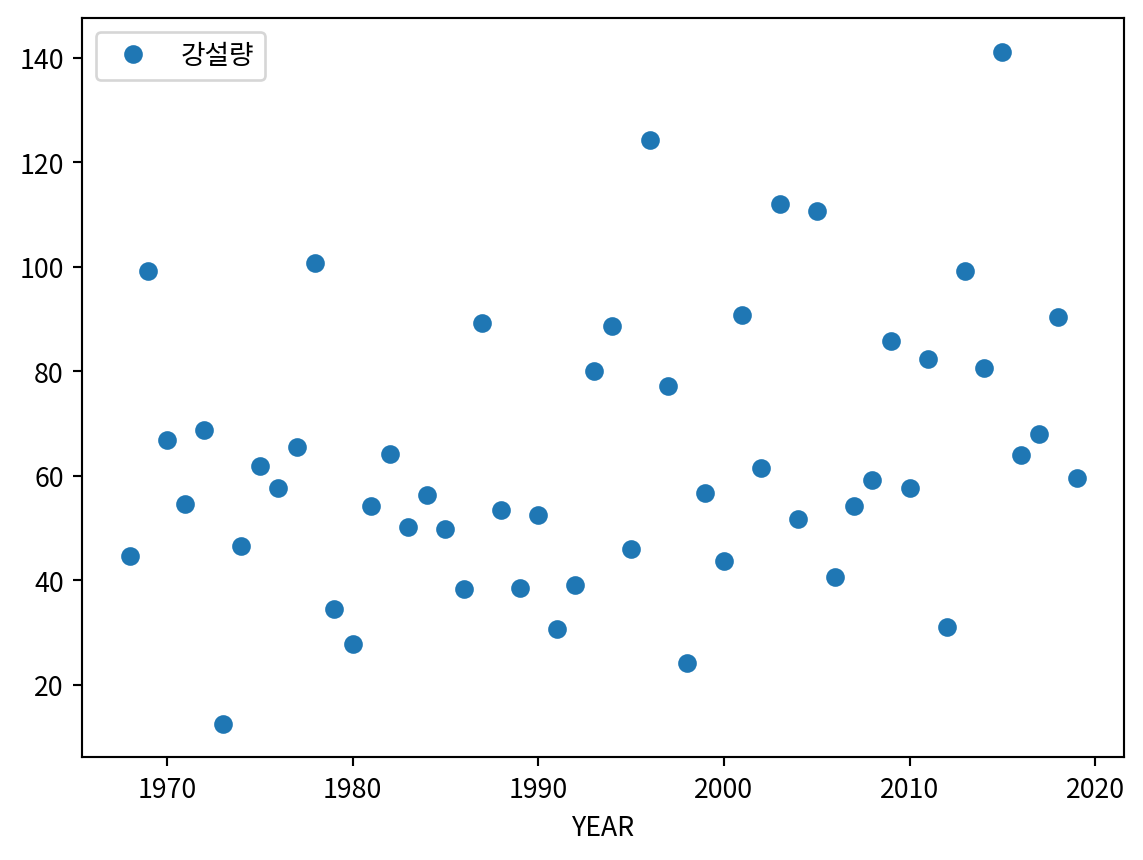
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Noto Sans KR'
df = pd.read_csv('https://github.com/AllenDowney/ThinkBayes2/raw/master/data/2239075.csv', parse_dates=[2])
df['YEAR'] = df['DATE'].dt.year
snow = df.groupby('YEAR')['SNOW'].sum()
snow = snow.iloc[1:-1]
snow.plot(ls='', marker='o', label='강설량')
plt.legend()