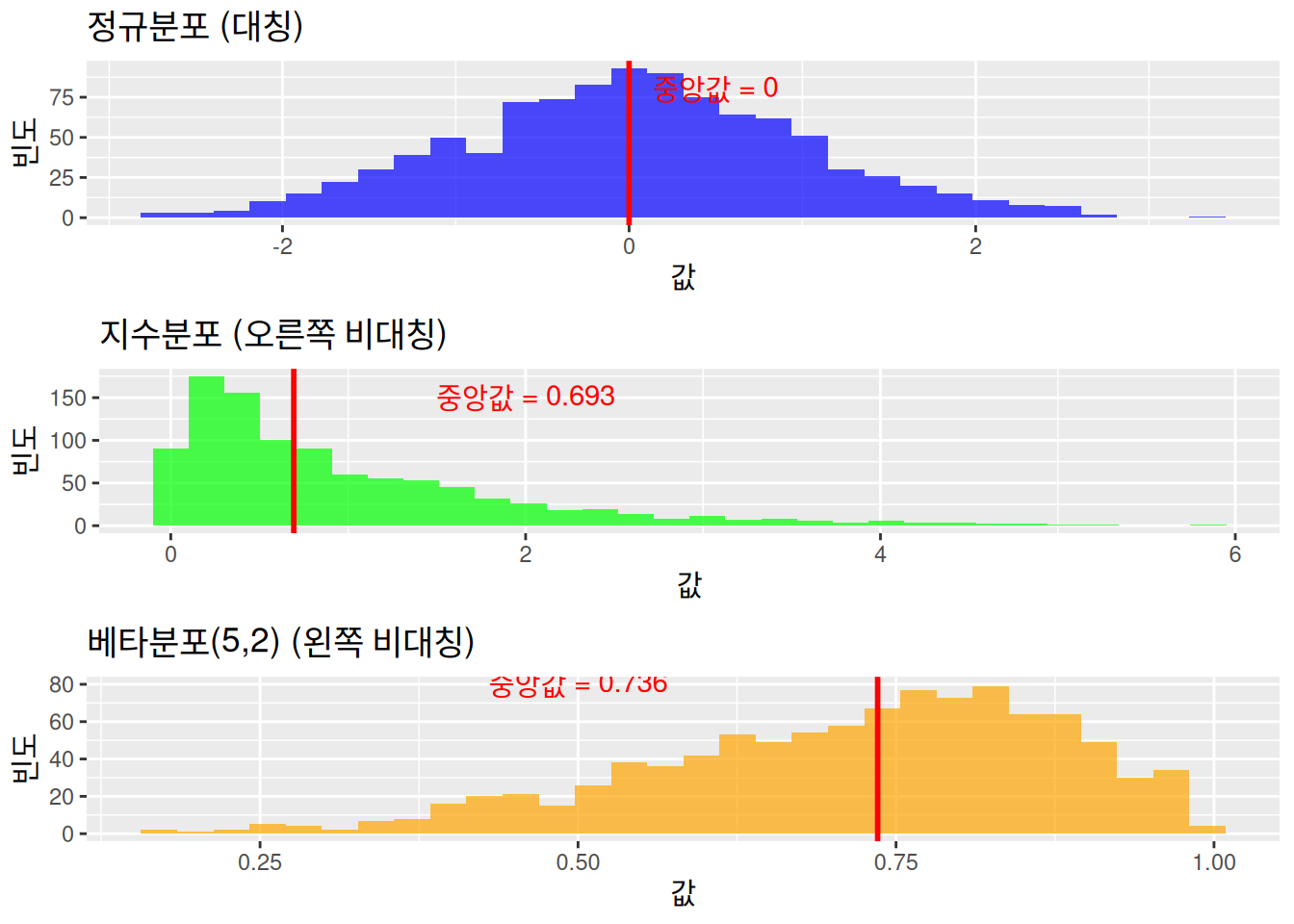
# 각 분포의 형태와 중앙값 시각화library(ggplot2)library(gridExtra)set.seed(123)x_normal <-rnorm(1000)x_exp <-rexp(1000)x_beta <-rbeta(1000, 5, 2)p1 <-ggplot() +geom_histogram(aes(x = x_normal), bins =30, alpha =0.7, fill ="blue") +geom_vline(xintercept =0, color ="red", size =1) +labs(title ="정규분포 (대칭)", x ="값", y ="빈도") +annotate("text", x =0.5, y =80, label ="중앙값 = 0", color ="red")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
p2 <-ggplot() +geom_histogram(aes(x = x_exp), bins =30, alpha =0.7, fill ="green") +geom_vline(xintercept =log(2), color ="red", size =1) +labs(title ="지수분포 (오른쪽 비대칭)", x ="값", y ="빈도") +annotate("text", x =2, y =150, label =paste("중앙값 =", round(log(2), 3)), color ="red")p3 <-ggplot() +geom_histogram(aes(x = x_beta), bins =30, alpha =0.7, fill ="orange") +geom_vline(xintercept =qbeta(0.5, 5, 2), color ="red", size =1) +labs(title ="베타분포(5,2) (왼쪽 비대칭)", x ="값", y ="빈도") +annotate("text", x =0.5, y =80, label =paste("중앙값 =", round(qbeta(0.5, 5, 2), 3)), color ="red")grid.arrange(p1, p2, p3, ncol =1)
결론: 시뮬레이션 결과에서 볼 수 있듯이, 분포가 대칭이든 비대칭이든 부호검정의 신뢰구간 포함률(coverage rate)은 명목 신뢰수준(95%)에 근접합니다. 이는 부호검정 신뢰구간이 분포무관(distribution-free) 성질을 가지기 때문입니다.
부호검정 사용 시 주의사항
동일한 값 처리: 중앙값과 정확히 같은 값들은 검정에서 제외
표본 크기: 작은 표본에서는 정확한 이항분포 사용, 큰 표본에서는 정규분포 근사
검정 방향: 양측검정 vs 단측검정 선택 중요
가정: 표본이 연속분포에서 추출되었다고 가정
윌콕슨 부호순위검정
모집단이 대칭인 경우 사용 가능
rank가 동점인 경우 평균으로 처리
영분포는 잘 알려져 있지 않은 분포
평균: \(\frac{n(n+1)}{4}\)
분산: \(\frac{n(n+1)(2n+1)}{24}\)
일반적으로 resampling 방식으로 구하고, 수가 많아지면 표준정규분포로 근사해서 계산(Lyapunov의 중심극한정리)